
Machine Learning Software: Design and Practical Use
Chih-Jen Lin National Taiwan University eBay Research Labs
Talk at Machine Learning Summer School, Kyoto, August 31, 2012
Chih-Jen Lin (National Taiwan Univ.) 1 / 102
The development of machine learning software involves many issues beyond theory and algorithms. We need to consider numerical computation, code readability, system usability, user-interface design, maintenance, long-term support, and many others. In this talk, we take two popular machine learning packages, LIBSVM and LIBLINEAR, as examples. We have been actively developing them in the past decade. In the first part of this talk, we demonstrate the practical use of these two packages by running some real experiments. We give examples to see how users make mistakes or inappropriately apply machine learning techniques. This part of the course also serves as a useful practical guide to support vector machines (SVM) and related methods. In the second part, we discuss design considerations in developing machine learning packages. We argue that many issues other than prediction accuracy are also very important.
Scroll with j/k | | | Size

Machine Learning Software: Design and Practical Use
Chih-Jen Lin National Taiwan University eBay Research Labs
Talk at Machine Learning Summer School, Kyoto, August 31, 2012
Chih-Jen Lin (National Taiwan Univ.) 1 / 102
1

Machine Learning Software
Most machine learning works focus on developing algorithms Researchers didnt pay much attention to software Recently, some think software is important. For example, The need for open source software in machine learning by Sonnenburg et al. (2007) One reasons is for replicating and evaluating research results However, a good software package is beyond that
Chih-Jen Lin (National Taiwan Univ.) 2 / 102
2

Machine Learning Software (Contd)
In this talk, I will share our experiences in developing LIBSVM and LIBLINEAR. LIBSVM (Chang and Lin, 2011): One of the most popular SVM packages; cited more than 10, 000 times on Google Scholar LIBLINEAR (Fan et al., 2008): A library for large linear classication; popular in Internet companies for document classication and NLP applications
Chih-Jen Lin (National Taiwan Univ.) 3 / 102
3

Machine Learning Software (Contd)
This talk will contain two parts: First, we discuss practical use of SVM as an example to see how users apply a machine learning method Second, we discuss design considerations for a good machine learning package. The talk is biased toward SVM and logistic regression, but materials are useful for other machine learning methods.
Chih-Jen Lin (National Taiwan Univ.)
4 / 102
4

Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
5 / 102
5

Practical use of SVM
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
6 / 102
6

Practical use of SVM
SVM introduction
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
7 / 102
7

Practical use of SVM
SVM introduction
Support Vector Classication
Training data (xi , yi ), i = 1, . . . , l, xi R n , yi = 1 Maximizing the margin (Boser et al., 1992; Cortes and Vapnik, 1995) min
w,b
1 T w w+C 2
l
max(1 yi (wT (xi ) + b), 0)
i=1
High dimensional ( maybe innite ) feature space (x) = (1 (x), 2 (x), . . .). w: maybe innite variables
Chih-Jen Lin (National Taiwan Univ.) 8 / 102
8
![Slide: Practical use of SVM
SVM introduction
Support Vector Classication (Contd)
The dual problem (nite # variables) 1 T Q eT min 2 subject to 0 i C , i = 1, . . . , l yT = 0, where Qij = yi yj (xi )T (xj ) and e = [1, . . . , 1]T At optimum w=
l i=1 i yi (xi )
Kernel: K (xi , xj ) (xi )T (xj ) ; closed form Example: Gaussian (RBF) kernel: e
Chih-Jen Lin (National Taiwan Univ.)
xi xj
2
9 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_009.png)
Practical use of SVM
SVM introduction
Support Vector Classication (Contd)
The dual problem (nite # variables) 1 T Q eT min 2 subject to 0 i C , i = 1, . . . , l yT = 0, where Qij = yi yj (xi )T (xj ) and e = [1, . . . , 1]T At optimum w=
l i=1 i yi (xi )
Kernel: K (xi , xj ) (xi )T (xj ) ; closed form Example: Gaussian (RBF) kernel: e
Chih-Jen Lin (National Taiwan Univ.)
xi xj
2
9 / 102
9
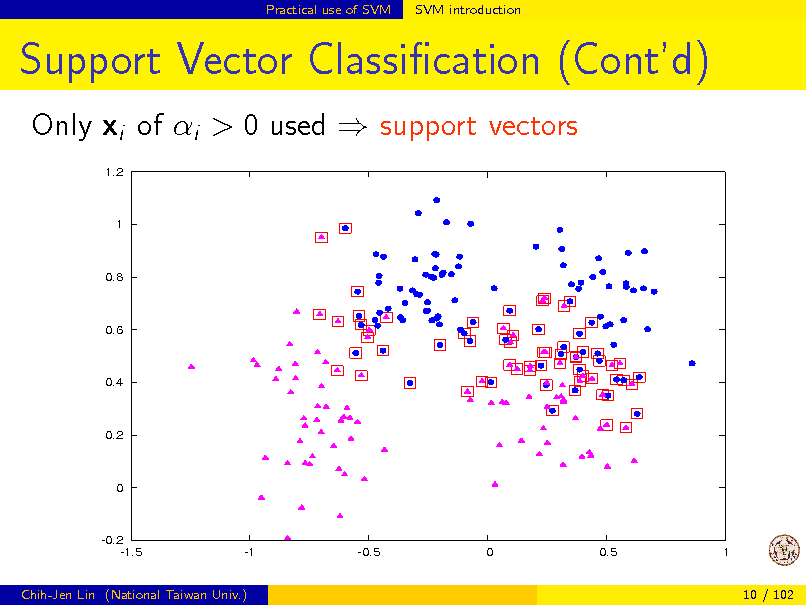
Practical use of SVM
SVM introduction
Support Vector Classication (Contd)
Only xi of i > 0 used support vectors
1.2 1
0.8
0.6
0.4
0.2
0
-0.2 -1.5
-1
-0.5
0
0.5
1
Chih-Jen Lin (National Taiwan Univ.)
10 / 102
10

Practical use of SVM
SVM introduction
Status of Support Vector Machines
SVM was introduced with kernels But ironically, the linear setting also helps SVM to become popular By linear we mean data are not mapped to a higher dimensional space There are many dierences between using kernel or not Many people are confused about this; so I will clarify the dierences in the next few slides
Chih-Jen Lin (National Taiwan Univ.) 11 / 102
11

Practical use of SVM
SVM introduction
Linear and Kernel Classication
Methods such as SVM and logistic regression can used in two ways Kernel methods: data mapped to a higher dimensional space x (x) (xi )T (xj ) easily calculated; little control on () Linear classication + feature engineering: We have x without mapping. Alternatively, we can say that (x) is our x; full control on x or (x) We refer to them as kernel and linear classiers
Chih-Jen Lin (National Taiwan Univ.) 12 / 102
12

Practical use of SVM
SVM introduction
Linear and Kernel Classication (Contd)
Lets check the prediction cost wT x + b versus
l i=1
i K (xi , x) + b
If K (xi , xj ) takes O(n), then O(n) versus O(nl)
Linear is much cheaper Deciding whether using kernel is cost-eective is still a big issue
Chih-Jen Lin (National Taiwan Univ.) 13 / 102
13

Practical use of SVM
SVM introduction
Linear and Kernel Classication (Contd)
For certain problems, accuracy by linear is as good as nonlinear But training and testing are much faster Especially document classication Number of features (bag-of-words model) very large Recently linear classication is a popular research topic. Sample works in 2005-2008: Joachims (2006); Shalev-Shwartz et al. (2007); Hsieh et al. (2008) They focus on large sparse data There are many other recent papers and software
Chih-Jen Lin (National Taiwan Univ.) 14 / 102
14
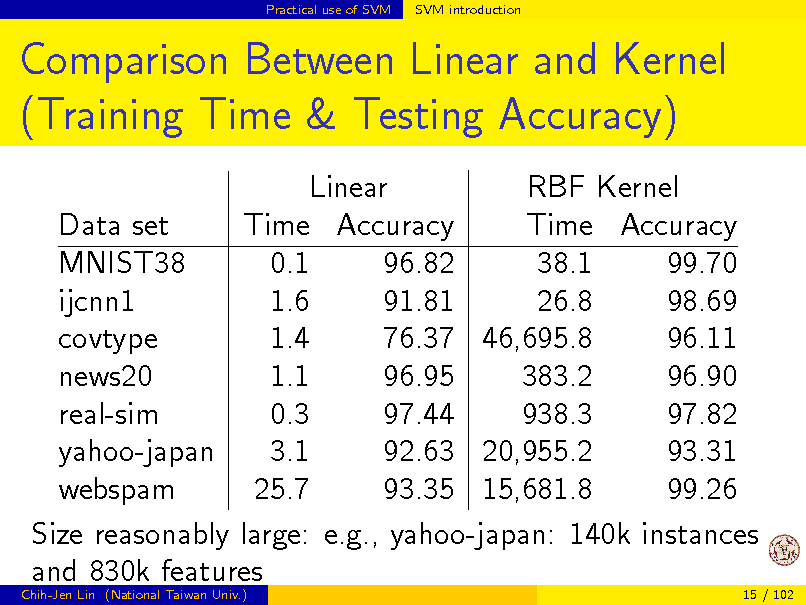
Practical use of SVM
SVM introduction
Comparison Between Linear and Kernel (Training Time & Testing Accuracy)
Linear RBF Kernel Data set Time Accuracy Time Accuracy MNIST38 0.1 96.82 38.1 99.70 ijcnn1 1.6 91.81 26.8 98.69 1.4 76.37 46,695.8 96.11 covtype news20 1.1 96.95 383.2 96.90 0.3 97.44 938.3 97.82 real-sim yahoo-japan 3.1 92.63 20,955.2 93.31 webspam 25.7 93.35 15,681.8 99.26 Size reasonably large: e.g., yahoo-japan: 140k instances and 830k features
Chih-Jen Lin (National Taiwan Univ.) 15 / 102
15
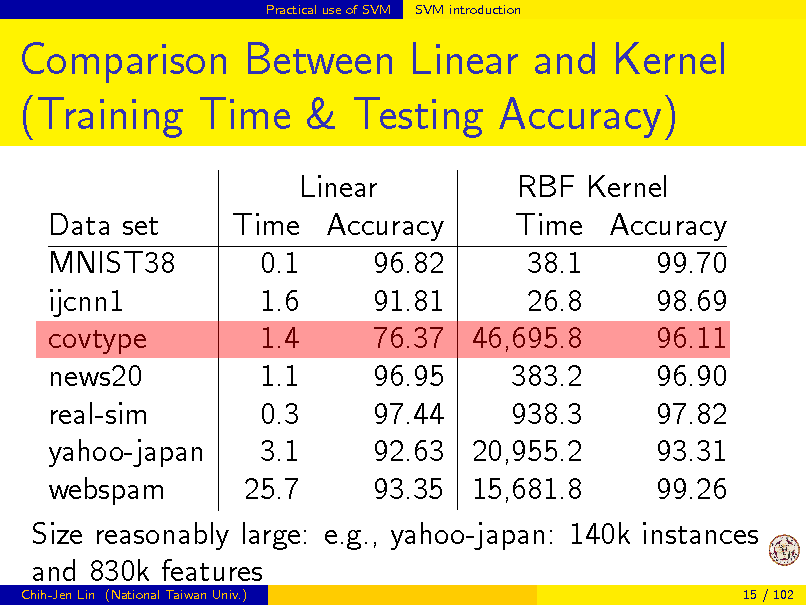
Practical use of SVM
SVM introduction
Comparison Between Linear and Kernel (Training Time & Testing Accuracy)
Linear RBF Kernel Data set Time Accuracy Time Accuracy MNIST38 0.1 96.82 38.1 99.70 ijcnn1 1.6 91.81 26.8 98.69 1.4 76.37 46,695.8 96.11 covtype news20 1.1 96.95 383.2 96.90 0.3 97.44 938.3 97.82 real-sim yahoo-japan 3.1 92.63 20,955.2 93.31 webspam 25.7 93.35 15,681.8 99.26 Size reasonably large: e.g., yahoo-japan: 140k instances and 830k features
Chih-Jen Lin (National Taiwan Univ.) 15 / 102
16
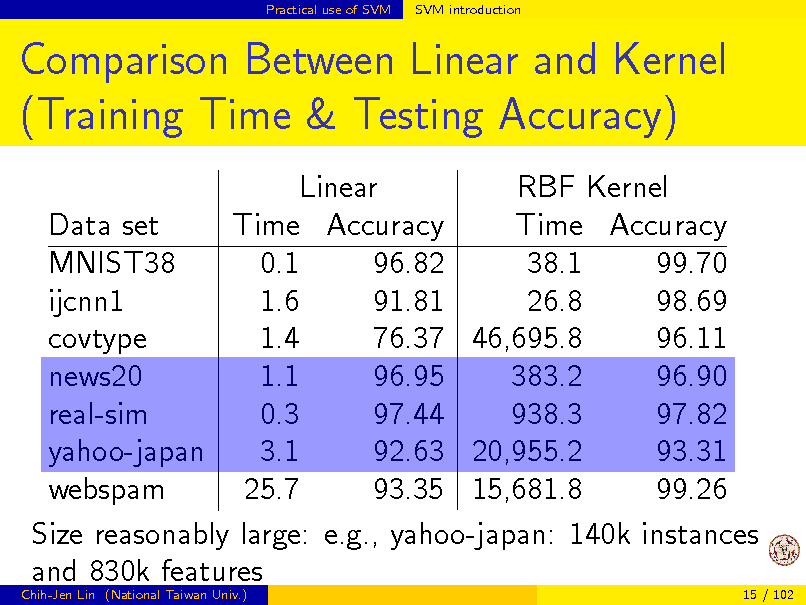
Practical use of SVM
SVM introduction
Comparison Between Linear and Kernel (Training Time & Testing Accuracy)
Linear RBF Kernel Data set Time Accuracy Time Accuracy MNIST38 0.1 96.82 38.1 99.70 ijcnn1 1.6 91.81 26.8 98.69 1.4 76.37 46,695.8 96.11 covtype news20 1.1 96.95 383.2 96.90 0.3 97.44 938.3 97.82 real-sim yahoo-japan 3.1 92.63 20,955.2 93.31 webspam 25.7 93.35 15,681.8 99.26 Size reasonably large: e.g., yahoo-japan: 140k instances and 830k features
Chih-Jen Lin (National Taiwan Univ.) 15 / 102
17

Practical use of SVM
SVM introduction
Summary: Support Vector Machines
The signicant dierences between linear and kernel motivated us to separately develop LIBSVM and LIBLINEAR For recent advances of linear classication, you may check a survey by Yuan et al. (2012) Today I will discuss only the situation of using kernels Another thing I didnt mention is online and oine training. We consider only oine training here
Chih-Jen Lin (National Taiwan Univ.) 16 / 102
18

Practical use of SVM
SVM introduction
Summary: Support Vector Machines (Contd)
So far I only gave a very brief introduction of support vector classication Today I am not giving a tutorial on SVM. For details of this method, you can check my other tutorial talks (e.g., the one at ACML 2010)
Chih-Jen Lin (National Taiwan Univ.)
17 / 102
19

Practical use of SVM
A real example
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
18 / 102
20

Practical use of SVM
A real example
How People Use SVM?
For most users, what they hope is 1. Prepare training and testing sets 2. Run a package and get good results But things are not that simple Lets start with a practical example from a user
Chih-Jen Lin (National Taiwan Univ.)
19 / 102
21

Practical use of SVM
A real example
Lets Try a Practical Example
A problem from astroparticle physics 1 1 1 0 0 0 2.61e+01 5.70e+01 1.72e+01 2.39e+01 2.23e+01 1.64e+01 5.88e+01 -1.89e-01 1.25e+02 2.21e+02 8.60e-02 1.22e+02 1.73e+02 -1.29e-01 1.25e+02 3.89e+01 4.70e-01 1.25e+02 2.26e+01 2.11e-01 1.01e+02 3.92e+01 -9.91e-02 3.24e+01
Training and testing sets available: 3,089 and 4,000 Data available at LIBSVM Data Sets
Chih-Jen Lin (National Taiwan Univ.) 20 / 102
22

Practical use of SVM
A real example
The Story Behind this Data Set
User: I am using libsvm in a astroparticle physics application .. First, let me congratulate you to a really easy to use and nice package. Unfortunately, it gives me astonishingly bad results... OK. Please send us your data I am able to get 97% test accuracy. Is that good enough for you ? User: You earned a copy of my PhD thesis
Chih-Jen Lin (National Taiwan Univ.) 21 / 102
23

Practical use of SVM
A real example
The Story Behind this Data Set (Contd)
What we have seen over the years is that Users expect good results right after using a method If method A doesnt work, they switch to B They may inappropriately use most methods they tried But isnt it machine learning peoples responsibility to make their methods easily give reasonable results?
Chih-Jen Lin (National Taiwan Univ.)
22 / 102
24

Practical use of SVM
A real example
The Story Behind this Data Set (Contd)
In my opinion Machine learning packages should provide some simple and automatic/semi-automatic settings for users These setting may not be the best, but easily give users some reasonable results If such settings are not enough, users many need to consult with machine learning experts. I will illustrate the rst point by a procedure we developed for SVM beginners
Chih-Jen Lin (National Taiwan Univ.) 23 / 102
25

Practical use of SVM
A real example
Training and Testing
Training the set svmguide1 to obtain svmguide1.model $./svm-train svmguide1 Testing the set svmguide1.t $./svm-predict svmguide1.t svmguide1.model out Accuracy = 66.925% (2677/4000) We see that training and testing accuracy are very dierent. Training accuracy is almost 100% $./svm-predict svmguide1 svmguide1.model out Accuracy = 99.7734% (3082/3089)
Chih-Jen Lin (National Taiwan Univ.) 24 / 102
26

Practical use of SVM
A real example
Why this Fails
Gaussian kernel is used here We see that most kernel elements have Kij = e
xi xj
2
/4
= 1 if i = j, 0 if i = j.
because some features in large numeric ranges For what kind of data, K I?
Chih-Jen Lin (National Taiwan Univ.) 25 / 102
27
![Slide: Practical use of SVM
A real example
Why this Fails (Contd)
If we have training data (x1 ) = [1, 0, . . . , 0]T . . . (xl ) = [0, . . . , 0, 1]T then K =I Clearly such training data can be correctly separated, but how about testing data? So overtting occurs
Chih-Jen Lin (National Taiwan Univ.) 26 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_028.png)
Practical use of SVM
A real example
Why this Fails (Contd)
If we have training data (x1 ) = [1, 0, . . . , 0]T . . . (xl ) = [0, . . . , 0, 1]T then K =I Clearly such training data can be correctly separated, but how about testing data? So overtting occurs
Chih-Jen Lin (National Taiwan Univ.) 26 / 102
28

Practical use of SVM
A real example
Overtting
See the illustration in the next slide In theory You can easily achieve 100% training accuracy This is useless When training and predicting a data, we should Avoid undertting: small training error Avoid overtting: small testing error
Chih-Jen Lin (National Taiwan Univ.)
27 / 102
29

Practical use of SVM
A real example
G and L: training;
and
: testing
Chih-Jen Lin (National Taiwan Univ.)
28 / 102
30
![Slide: Practical use of SVM
A real example
Data Scaling
Without scaling, the above overtting situation may occur Also, features in greater numeric ranges may dominate A simple solution is to linearly scale each feature to [0, 1] by: feature value min , max min There are many other scaling methods Scaling generally helps, but not always
Chih-Jen Lin (National Taiwan Univ.) 29 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_031.png)
Practical use of SVM
A real example
Data Scaling
Without scaling, the above overtting situation may occur Also, features in greater numeric ranges may dominate A simple solution is to linearly scale each feature to [0, 1] by: feature value min , max min There are many other scaling methods Scaling generally helps, but not always
Chih-Jen Lin (National Taiwan Univ.) 29 / 102
31
![Slide: Practical use of SVM
A real example
Data Scaling: Same Factors
A common mistake
$./svm-scale -l -1 -u 1 svmguide1 > svmguide1.sc $./svm-scale -l -1 -u 1 svmguide1.t > svmguide1. -l -1 -u 1: scaling to [1, 1] We need to use same factors on training and testing
$./svm-scale -s range1 svmguide1 > svmguide1.sca $./svm-scale -r range1 svmguide1.t > svmguide1.t Later we will give a real example
Chih-Jen Lin (National Taiwan Univ.) 30 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_032.png)
Practical use of SVM
A real example
Data Scaling: Same Factors
A common mistake
$./svm-scale -l -1 -u 1 svmguide1 > svmguide1.sc $./svm-scale -l -1 -u 1 svmguide1.t > svmguide1. -l -1 -u 1: scaling to [1, 1] We need to use same factors on training and testing
$./svm-scale -s range1 svmguide1 > svmguide1.sca $./svm-scale -r range1 svmguide1.t > svmguide1.t Later we will give a real example
Chih-Jen Lin (National Taiwan Univ.) 30 / 102
32

Practical use of SVM
A real example
After Data Scaling
Train scaled data and then predict
$./svm-train svmguide1.scale $./svm-predict svmguide1.t.scale svmguide1.scale svmguide1.t.predict Accuracy = 96.15% Training accuracy is now similar
$./svm-predict svmguide1.scale svmguide1.scale.m Accuracy = 96.439% For this experiment, we use parameters C = 1, = 0.25, but sometimes performances are sensitive to parameters
Chih-Jen Lin (National Taiwan Univ.) 31 / 102
33

Practical use of SVM
Parameter selection
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
32 / 102
34

Practical use of SVM
Parameter selection
Parameters versus Performances
If we use C = 20, = 400
$./svm-train -c 20 -g 400 svmguide1.scale $./svm-predict svmguide1.scale svmguide1.sca Accuracy = 100% (3089/3089)
100% training accuracy but $./svm-predict svmguide1.t.scale svmguide1.s Accuracy = 82.7% (3308/4000) Very bad test accuracy Overtting happens
Chih-Jen Lin (National Taiwan Univ.) 33 / 102
35

Practical use of SVM
Parameter selection
Parameter Selection
For SVM, we may need to select suitable parameters They are C and kernel parameters Example: of e
xi xj
2
a, b, d of (xT xj /a + b)d i How to select them so performance is better?
Chih-Jen Lin (National Taiwan Univ.)
34 / 102
36

Practical use of SVM
Parameter selection
Performance Evaluation
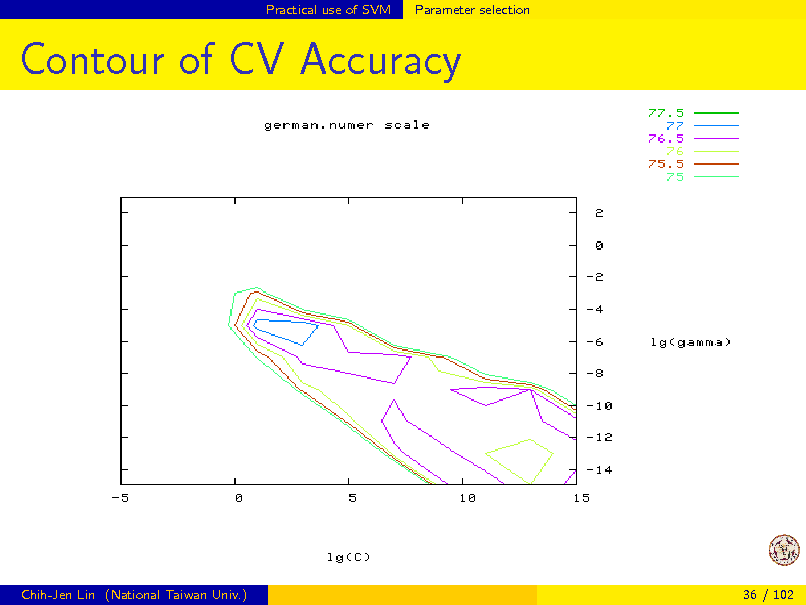
Available data training and validation Train the training; test the validation to estimate the performance A common way is k-fold cross validation (CV): Data randomly separated to k groups Each time k 1 as training and one as testing Select parameters/kernels with best CV result There are many other methods to evaluate the performance
Chih-Jen Lin (National Taiwan Univ.) 35 / 102
37
Practical use of SVM
Parameter selection
Contour of CV Accuracy
Chih-Jen Lin (National Taiwan Univ.)
36 / 102
38

Practical use of SVM
Parameter selection
The good region of parameters is quite large SVM is sensitive to parameters, but not that sensitive Sometimes default parameters work but its good to select them if time is allowed
Chih-Jen Lin (National Taiwan Univ.)
37 / 102
39

Practical use of SVM
Parameter selection
Example of Parameter Selection
Direct training and test $./svm-train svmguide3 $./svm-predict svmguide3.t svmguide3.model o Accuracy = 2.43902% After data scaling, accuracy is still low
$./svm-scale -s range3 svmguide3 > svmguide3.sca $./svm-scale -r range3 svmguide3.t > svmguide3.t $./svm-train svmguide3.scale $./svm-predict svmguide3.t.scale svmguide3.scale Accuracy = 12.1951%
Chih-Jen Lin (National Taiwan Univ.) 38 / 102
40

Practical use of SVM
Parameter selection
Example of Parameter Selection (Contd)
Select parameters by trying a grid of (C , ) values $ python grid.py svmguide3.scale 128.0 0.125 84.8753 (Best C =128.0, =0.125 with ve-fold cross-validation rate=84.8753%) Train and predict using the obtained parameters
$ ./svm-train -c 128 -g 0.125 svmguide3.scale $ ./svm-predict svmguide3.t.scale svmguide3.scal Accuracy = 87.8049%
Chih-Jen Lin (National Taiwan Univ.) 39 / 102
41

Practical use of SVM
Parameter selection
Selecting Kernels
RBF, polynomial, or others? For beginners, use RBF rst Linear kernel: special case of RBF Accuracy of linear the same as RBF under certain parameters (Keerthi and Lin, 2003) Polynomial kernel: (xT xj /a + b)d i Numerical diculties: (< 1)d 0, (> 1)d More parameters than RBF
Chih-Jen Lin (National Taiwan Univ.) 40 / 102
42

Practical use of SVM
Parameter selection
A Simple Procedure for Beginners
After helping many users, we came up with the following procedure 1. Conduct simple scaling on the data 2 2. Consider RBF kernel K (x, y) = e xy 3. Use cross-validation to nd the best parameter C and 4. Use the best C and to train the whole training set 5. Test In LIBSVM, we have a python script easy.py implementing this procedure.
Chih-Jen Lin (National Taiwan Univ.) 41 / 102
43

Practical use of SVM
Parameter selection
A Simple Procedure for Beginners (Contd)
We proposed this procedure in an SVM guide (Hsu et al., 2003) and implemented it in LIBSVM From research viewpoints, this procedure is not novel. We never thought about submiting our guide somewhere But this procedure has been tremendously useful. Now almost the standard thing to do for SVM beginners
Chih-Jen Lin (National Taiwan Univ.) 42 / 102
44
![Slide: Practical use of SVM
Parameter selection
A Real Example of Wrong Scaling
Separately scale each feature of training and testing data to [0, 1]
$ ../svm-scale -l 0 svmguide4 > svmguide4.scale $ ../svm-scale -l 0 svmguide4.t > svmguide4.t.sc $ python easy.py svmguide4.scale svmguide4.t.sca Accuracy = 69.2308% (216/312) (classification) The accuracy is low even after parameter selection
$ ../svm-scale -l 0 -s range4 svmguide4 > svmgui $ ../svm-scale -r range4 svmguide4.t > svmguide4 $ python easy.py svmguide4.scale svmguide4.t.sca Accuracy = 89.4231% (279/312) (classification)
Chih-Jen Lin (National Taiwan Univ.) 43 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_045.png)
Practical use of SVM
Parameter selection
A Real Example of Wrong Scaling
Separately scale each feature of training and testing data to [0, 1]
$ ../svm-scale -l 0 svmguide4 > svmguide4.scale $ ../svm-scale -l 0 svmguide4.t > svmguide4.t.sc $ python easy.py svmguide4.scale svmguide4.t.sca Accuracy = 69.2308% (216/312) (classification) The accuracy is low even after parameter selection
$ ../svm-scale -l 0 -s range4 svmguide4 > svmgui $ ../svm-scale -r range4 svmguide4.t > svmguide4 $ python easy.py svmguide4.scale svmguide4.t.sca Accuracy = 89.4231% (279/312) (classification)
Chih-Jen Lin (National Taiwan Univ.) 43 / 102
45
![Slide: Practical use of SVM
Parameter selection
A Real Example of Wrong Scaling (Contd)
With the correct setting, the 10 features in the test data svmguide4.t.scale have the following maximal values: 0.7402, 0.4421, 0.6291, 0.8583, 0.5385, 0.7407, 0.3982, 1.0000, 0.8218, 0.9874 Scaling the test set to [0, 1] generated an erroneous set.
Chih-Jen Lin (National Taiwan Univ.)
44 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_046.png)
Practical use of SVM
Parameter selection
A Real Example of Wrong Scaling (Contd)
With the correct setting, the 10 features in the test data svmguide4.t.scale have the following maximal values: 0.7402, 0.4421, 0.6291, 0.8583, 0.5385, 0.7407, 0.3982, 1.0000, 0.8218, 0.9874 Scaling the test set to [0, 1] generated an erroneous set.
Chih-Jen Lin (National Taiwan Univ.)
44 / 102
46

Design of machine learning software
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
45 / 102
47

Design of machine learning software
Users and their needs
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
46 / 102
48

Design of machine learning software
Users and their needs
Users Machine Learning Knowledge
When we started developing LIBSVM, we didnt know who our users are or whether we will get any Very soon we found that many users have zero machine learning knowledge It is unbelievable that many asked what the dierence between training and testing is
Chih-Jen Lin (National Taiwan Univ.)
47 / 102
49

Design of machine learning software
Users and their needs
Users Machine Learning Knowledge (Contd)
A sample mail From: To: cjlin@csie.ntu.edu.tw Subject: Doubt regarding SVM Date: Sun, 18 Jun 2006 10:04:01 Dear Sir, sir what is the difference between testing data and training data? Sometimes we cannot do much for such users.
Chih-Jen Lin (National Taiwan Univ.) 48 / 102
50

Design of machine learning software
Users and their needs
Users Machine Learning Knowledge (Contd)
Fortunately, more people have taken machine learning courses (or attended MLSS) On the other hand, because users are not machine learning researchers, some automatic or semi-automatic settings are helpful The simple procedure discussed earlier is an example Also, your target users aect your design. For example, we assume LIBLINEAR users are more experienced.
Chih-Jen Lin (National Taiwan Univ.) 49 / 102
51

Design of machine learning software
Users and their needs
We are Our Own Users
You may ask why we care non-machine learning users so much The reason is that we were among them before My background is in optimization. When we started working on SVM, we tried some UCI sets. We failed to obtain similar accuracy values in papers Through a painful process we learned that scaling may be needed
Chih-Jen Lin (National Taiwan Univ.)
50 / 102
52

Design of machine learning software
Users and their needs
We are Our Own Users (Contd)
Machine learning researchers sometimes failed to see the diculties of general users. As users of our own software, we constantly think about diculties others may face
Chih-Jen Lin (National Taiwan Univ.)
51 / 102
53

Design of machine learning software
Users and their needs
Users are Our Teachers
While we criticize users lack of machine learning knowledge, they help to point out many useful directions Example: LIBSVM supported only binary classication in the beginning. From many users requests, we knew the importance of multi-class classication There are many possible approaches for multi-class SVM. Assume data are in k classes
Chih-Jen Lin (National Taiwan Univ.)
52 / 102
54

Design of machine learning software
Users and their needs
Users are Our Teachers (Contd)
- One-against-the rest: Train k binary SVMs: 1st class 2nd class vs. vs. . . . (2, , k)th class (1, 3, . . . , k)th class
- One-against-one: train k(k 1)/2 binary SVMs (1, 2), (1, 3), . . . , (1, k), (2, 3), (2, 4), . . . , (k 1, k) We nished a study in Hsu and Lin (2002), which is now well cited. Currently LIBSVM supports one-vs-one approach
Chih-Jen Lin (National Taiwan Univ.) 53 / 102
55

Design of machine learning software
Users and their needs
Users are Our Teachers (Contd)
LIBSVM is among the rst SVM software to handle multi-class data. This helps to attract many users. Users help to identify useful things for the software They even help to identify important research directions The paper (Hsu and Lin, 2002) was rejected by many places because its a detailed comparison without new algorithms But from users we knew its results are important. This paper is now one of my most cited papers
Chih-Jen Lin (National Taiwan Univ.) 54 / 102
56

Design of machine learning software
Design considerations
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
55 / 102
57

Design of machine learning software
Design considerations
One or Many Options
Sometimes we received the following requests 1. In addition to one-vs-one, could you include other multi-class approaches such as one-vs-the rest? 2. Could you extend LIBSVM to support other kernels such as 2 kernel? Two extremes in designing a software package 1. One option: reasonably good for most cases 2. Many options: users try options to get best results
Chih-Jen Lin (National Taiwan Univ.) 56 / 102
58

Design of machine learning software
Design considerations
One or Many Options (Contd)
From a research viewpoint, we should include everything, so users can play with them But more options more powerful more complicated Some users have no abilities to choose between options Example: Some need 2 kernel, but some have no idea what it is
Chih-Jen Lin (National Taiwan Univ.) 57 / 102
59

Design of machine learning software
Design considerations
One or Many Options (Contd)
Users often try all options even if thats not needed Example: LIBLINEAR has the following solvers
options: -s type : set type of solver (default 1) 0 -- L2-regularized logistic regression (primal) ... 7 -- L2-regularized logistic regression (dual) Some users told me: I have tried all solvers, but accuracy is similar But wait, doesnt solvers 0 and 7 always give same accuracy? No need to run both
Chih-Jen Lin (National Taiwan Univ.) 58 / 102
60

Design of machine learning software
Design considerations
One or Many Options (Contd)
For LIBSVM, we basically took the one option approach We are very careful in adding things to LIBSVM However, users do have dierent needs. For example, some need precision/recall rather than accuracy We end up with developing another web site LIBSVM Tools to serve users special needs
Chih-Jen Lin (National Taiwan Univ.)
59 / 102
61

Design of machine learning software
Design considerations
One or Many Options (Contd)
Sample code in LIBSVM tools - Cross Validation with Dierent Criteria (AUC, F-score, etc.) - ROC Curve for Binary SVM - LIBSVM for string data Not sure if this is the best way, but seems ok so far Another advantage is we can maintain high quality for the core package. Things in LIBSVM Tools are less well maintained.
Chih-Jen Lin (National Taiwan Univ.) 60 / 102
62

Design of machine learning software
Design considerations
Simplicity versus Better Performance
This issue is related to one or many options discussed before Example: Before, our cross validation (CV) procedure is not stratied - Results less stable because data of each class not evenly distributed to folds - We now support stratied CV, but code becomes more complicated In general, we avoid changes for just marginal improvements
Chih-Jen Lin (National Taiwan Univ.) 61 / 102
63

Design of machine learning software
Design considerations
Simplicity versus Better Performance (Contd)
A recent Google research blog Lessons learned developing a practical large scale machine learning system by Simon Tong From the blog, It is perhaps less academically interesting to design an algorithm that is slightly worse in accuracy, but that has greater ease of use and system reliability. However, in our experience, it is very valuable in practice. That is, a complicated method with a slightly higher accuracy may not be useful in practice
Chih-Jen Lin (National Taiwan Univ.) 62 / 102
64
Design of machine learning software
Design considerations
Simplicity versus Better Performance (Contd)
Example: LIBSVM uses a grid search to nd two parameters C and . We may think this is simple and naive
Chih-Jen Lin (National Taiwan Univ.)
63 / 102
65

Design of machine learning software
Design considerations
Simplicity versus Better Performance (Contd)
Indeed, we studied loo bound in detail. That is, a function of parameters f (C , ) is derived to satisfy leave-one-out error f (C , ) Then we solve min f (C , )
C ,
Results not very stable because f (C , ) is only an approximation. Implementation is quite complicated. For only two parameters, a simple grid search may be a suitable choice
Chih-Jen Lin (National Taiwan Univ.) 64 / 102
66

Design of machine learning software
Design considerations
Numerical and Optimization Methods
Many classication methods involve numerical and optimization procedures A key point is that we need to take machine learning properties into the design of your implementation An example in Lievens talk yesterday: L1-regularized least-square regression I will discuss some SVM examples
Chih-Jen Lin (National Taiwan Univ.)
65 / 102
67

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
Lets consider SVM dual 1 T Q eT min 2 subject to 0 i C , i = 1, . . . , l yT = 0 Qij = 0, Q : an l by l fully dense matrix 50,000 training points: 50,000 variables: (50, 0002 8/2) bytes = 10GB RAM to store Q Traditional optimization methods: Newton or gradient cannot be directly applied
Chih-Jen Lin (National Taiwan Univ.) 66 / 102
68

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
One workaround is to work on some variables each time (e.g., Osuna et al., 1997; Joachims, 1998; Platt, 1998) Working set B , N = {1, . . . , l}\B xed Sub-problem at the kth iteration: min
B
1 T QBB QBN B (k )T N QNB QNN 2 B eT (ek )T B N k N
B k N
subject to
Chih-Jen Lin (National Taiwan Univ.)
T T 0 t C , t B, yB B = yN k N
67 / 102
69

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
The new objective function 1 T B QBB B + (eB + QBN k )T B + constant N 2 Only B columns of Q needed (|B| 2) Calculated when used Trade time for space But is such an approach practical?
Chih-Jen Lin (National Taiwan Univ.) 68 / 102
70

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
Convergence not very fast But, no need to have very accurate decision function:
l i=1
i K (xi , x) + b
Prediction may still be correct with a rough Further, in some situations, # support vectors # training points Initial 1 = 0, some instances never used So special properties of SVM did contribute to the viability of this method
Chih-Jen Lin (National Taiwan Univ.) 69 / 102
71

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
An example of training 50,000 instances using LIBSVM $svm-train -c 16 -g 4 -m 400 22features Total nSV = 3370 Time 79.524s On a Xeon 2.0G machine Calculating the whole Q takes more time #SVs = 3,370 50,000 A good case where some remain at zero all the time
Chih-Jen Lin (National Taiwan Univ.) 70 / 102
72

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
Another example: training kernel and linear SVM should be done by dierent methods Whats the dierence between kernel and linear? for linear, K can be written as XX T where T x1 . X = . R ln . xT l is the training matrix Note that n: # features, l: # data
Chih-Jen Lin (National Taiwan Univ.) 71 / 102
73

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
Recall in the kernel case, we need (Q)i 1, i B The cost is O(nl)
l j=1
yi yj K (xi , xj )j 1
Chih-Jen Lin (National Taiwan Univ.)
72 / 102
74

Design of machine learning software
Design considerations
Numerical and Optimization Methods (Contd)
For linear, if we have w then
l j=1 l j=1
yj j xj
yi yj xT xj j 1 = yi wT xi 1 i
costs only O(n). Details of maintaining w are not discussed here; the cost is also O(n) Again, the key is that properties of machine learning problems should be considered
Chih-Jen Lin (National Taiwan Univ.) 73 / 102
75

Design of machine learning software
Design considerations
Numerical Stability
Quality of the numerical programs is important for a machine learning package Numerical analysts have a high standard on their code, but unfortunately we machine learning people do not This situation is expected: If we put eorts on implementing method A and one day method B gives higher accuracy Eorts are wasted
Chih-Jen Lin (National Taiwan Univ.)
74 / 102
76

Design of machine learning software
Design considerations
Numerical Stability (Contd)
We will give an example to discuss how to improve numerical stability in your implementation In LIBSVMs probability outputs, we calculate (ti log(pi ) + (1 ti ) log(1 pi )) , 1 1 + exp() When is small, pi 1 Then 1 pi is a catastrophic cancellation pi
Chih-Jen Lin (National Taiwan Univ.) 75 / 102
where
77

Design of machine learning software
Design considerations
Numerical Stability (Contd)
Catastrophic cancellation (Goldberg, 1991): when subtracting two nearby numbers, the relative error can be large so most digits are meaningless. In a simple C++ program with double precision, = 64 but exp() gives more accurate result 1 + exp()
Chih-Jen Lin (National Taiwan Univ.) 76 / 102
1
1 returns zero 1 + exp()
78

Design of machine learning software
Design considerations
Numerical Stability (Contd)
Catastrophic cancellation may be resolved by reformulation Another issue is that log and exp could easily cause an overow If is large exp() Then pi = 1 0 1 + exp() log(pi )
Chih-Jen Lin (National Taiwan Univ.)
77 / 102
79

Design of machine learning software
Design considerations
We can use the following reformulation log(1 + exp()) = log(exp() (exp() + 1)) = + log(1 + exp()) When is large exp() 0 and log(1 + exp()) Less like to get overow because of no exp()
Chih-Jen Lin (National Taiwan Univ.)
78 / 102
80

Design of machine learning software
Design considerations
Numerical Stability (Contd)
In summary, (ti log pi + (1 ti ) log(1 pi )) = (ti 1) + log (1 + exp()) = ti () + log (1 + exp()) We implement (1) with the following rule: If 0 then use (3); Else use (2). This handles both issues of overow and catastrophic cancellation
Chih-Jen Lin (National Taiwan Univ.) 79 / 102
(1) (2) (3)
81

Design of machine learning software
Design considerations
Legacy Issues
The compatibility between earlier and later versions is an issue Such legacy issues restrict developers to conduct certain changes. We face a similar situation. For example, we chose one-vs-one as the multi-class strategy. This decision aects subsequent buildups. Example: in LIBSVM, multi-class probability outputs must follow the one-vs-one structure. For classes i and j, we obtain P(x in class i | x in class i or j),
Chih-Jen Lin (National Taiwan Univ.) 80 / 102
82

Design of machine learning software
Design considerations
Legacy Issues (Contd)
Then we need to couple all k results (k: the 2 number of classes) and obtain P(x in class i), i = 1, . . . , k. If we further develop multi-label methods, we are restricted to extend from one-versus-one multi-class strategy What if one day we would like to use a dierent multi-class method?
Chih-Jen Lin (National Taiwan Univ.) 81 / 102
83

Design of machine learning software
Design considerations
Legacy Issues (Contd)
In LIBSVM, we understand this legacy issue in the beginning Example: we did not make the trained model a public structure Encapsulation in object-oriented programming Here is the C code to train and test #include <svm.h> ... model = svm_train(...); ... predict_label = svm_predict(model,x); svm.h includes all public functions and structures
Chih-Jen Lin (National Taiwan Univ.) 82 / 102
84
![Slide: Design of machine learning software
Design considerations
Legacy Issues (Contd)
We decided not to put model structure in svm.h Instead we put it in svm.cpp User can call model = svm_train(...); but cannot directly access a models contents int y1 = model.label[1]; We provide functions so users can get some model information svm_get_svm_type(model); svm_get_nr_class(model); svm_get_labels(model, ...);
Chih-Jen Lin (National Taiwan Univ.) 83 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_085.png)
Design of machine learning software
Design considerations
Legacy Issues (Contd)
We decided not to put model structure in svm.h Instead we put it in svm.cpp User can call model = svm_train(...); but cannot directly access a models contents int y1 = model.label[1]; We provide functions so users can get some model information svm_get_svm_type(model); svm_get_nr_class(model); svm_get_labels(model, ...);
Chih-Jen Lin (National Taiwan Univ.) 83 / 102
85

Design of machine learning software
Design considerations
Documentation and Support
Any software needs good documents and support I cannot count how many mails my students and I replied. Maybe 20,000 or more. How to write good documents is an interesting issue Users may not understand what you wrote
Chih-Jen Lin (National Taiwan Univ.)
84 / 102
86

Design of machine learning software
Design considerations
Documentation and Support (Contd)
Here is an example: some users asked if LIBSVM supported multi-class classication I thought its well documented in README Finally I realized that users may not read the whole README. Instead, some of them check only the usage
Chih-Jen Lin (National Taiwan Univ.)
85 / 102
87
![Slide: Design of machine learning software
Design considerations
Documentation and Support (Contd)
They didnt see multi-class in the usage $ svm-train
Usage: svm-train [options] training_set_file options: -s svm_type : set type of SVM (default 0) 0 -- C-SVC 1 -- nu-SVC 2 -- one-class SVM 3 -- epsilon-SVR 4 -- nu-SVR ...
Chih-Jen Lin (National Taiwan Univ.) 86 / 102](https://yosinski.com/mlss12/media/slides/MLSS-2012-Lin-Machine-Learning-Software_088.png)
Design of machine learning software
Design considerations
Documentation and Support (Contd)
They didnt see multi-class in the usage $ svm-train
Usage: svm-train [options] training_set_file options: -s svm_type : set type of SVM (default 0) 0 -- C-SVC 1 -- nu-SVC 2 -- one-class SVM 3 -- epsilon-SVR 4 -- nu-SVR ...
Chih-Jen Lin (National Taiwan Univ.) 86 / 102
88

Design of machine learning software
Design considerations
Documentation and Support (Contd)
In the next version we will change the usage to -s svm_type : set type of SVM (default 0) 0 -- C-SVC (multi-class classificati 1 -- nu-SVC (multi-class classificati 2 -- one-class SVM 3 -- epsilon-SV (regression) 4 -- nu-SVR (regression) I am going to see how many asked why LIBSVM doesnt support two-class SVM
Chih-Jen Lin (National Taiwan Univ.)
87 / 102
89

Discussion and conclusions
Outline
1
Practical use of SVM SVM introduction A real example Parameter selection Design of machine learning software Users and their needs Design considerations Discussion and conclusions
2
3
Chih-Jen Lin (National Taiwan Univ.)
88 / 102
90

Discussion and conclusions
Software versus Experiment Code
Many researchers now release experiment code used for their papers Reason: experiments can be reproduced This is important, but experiment code is dierent from software Experiment code often includes messy scripts for various settings in the paper useful for reviewers Example: to check an implementation trick in a proposed algorithm, need to run with/without the trick
Chih-Jen Lin (National Taiwan Univ.) 89 / 102
91

Discussion and conclusions
Software versus Experiment Code (Contd)
Software: for general users One or a few reasonable settings with a suitable interface are enough Many are now willing to release their experimental code Basically you clean up the code after nishing a paper But working on and maintaining high-quality software take much more work
Chih-Jen Lin (National Taiwan Univ.) 90 / 102
92

Discussion and conclusions
Software versus Experiment Code (Contd)
Reproducibility dierent from replicability (Drummond, 2009) Replicability: make sure things work on the sets used in the paper Reproducibility: ensure that things work in general In my group, we release experiment code for every paper for replicability And carefully select and modify some results to our software (hopefully) for reproducibility
Chih-Jen Lin (National Taiwan Univ.) 91 / 102
93

Discussion and conclusions
Software versus Experiment Code (Contd)
The community now lacks incentives for researchers to work on high quality software JMLR recently started open source software section (4-page description of the software) This is a positive direction How to properly evaluate such papers is an issue Some software are very specic on a small problem, but some are more general
Chih-Jen Lin (National Taiwan Univ.)
92 / 102
94

Discussion and conclusions
Research versus Software Development
Shouldnt software be developed by companies? Two issues 1 Business models of machine learning software 2 Research problems in developing software
Chih-Jen Lin (National Taiwan Univ.)
93 / 102
95

Discussion and conclusions
Research versus Software Development (Contd)
Business model It is unclear to me what a good model should be Machine learning software are basically research software They are often called by some bigger packages For example, LIBSVM and LIBLINEAR are called by Weka and Rapidminer through interfaces These data mining packages are open sourced and their business is mainly on consulting Should we on the machine learning side use a similar way?
Chih-Jen Lin (National Taiwan Univ.) 94 / 102
96

Discussion and conclusions
Research versus Software Development (Contd)
Research issues A good machine learning package involves more than the core machine learning algorithms There are many other research issues - Numerical algorithms and their stability - Parameter tuning, feature generation, and user interfaces - Serious comparisons and system issues These issues need researchers rather than engineers Currently we lack a system to encourage machine learning researchers to study these issues.
Chih-Jen Lin (National Taiwan Univ.) 95 / 102
97

Discussion and conclusions
Machine Learning and Its Practical Use
I just mentioned that a machine learning package involves more than algorithms Here is an interesting conversation between me and a friend Me: Your company has system A for large-scale training and now also has system B. What are their dierences? My friend: A uses ... algorithms and B uses ... Me: But these algorithms are related My friend: Yes, but you know sometimes algorithms are the least important thing
Chih-Jen Lin (National Taiwan Univ.) 96 / 102
98

Discussion and conclusions
Machine Learning and Its Practical Use (Contd)
As machine learning researchers, of course we think algorithms are important But we must realize that in industry machine learning is often only part of a big project Moreover, it rarely is the most important component We academic machine learning people must try to know where machine learning is useful. Then we can develop better algorithms and software
Chih-Jen Lin (National Taiwan Univ.) 97 / 102
99

Discussion and conclusions
Conclusions
From my experience, developing machine learning software is very interesting. In particular, you get to know how your research work is used Through software, we have seen dierent application areas of machine learning We should encourage more researchers to develop high quality machine learning software
Chih-Jen Lin (National Taiwan Univ.)
98 / 102
100

Discussion and conclusions
Acknowledgments
All users have greatly helped us to make improvements Without them we cannot get this far We also thank all our past group members
Chih-Jen Lin (National Taiwan Univ.)
99 / 102
101

Discussion and conclusions
References I
B. E. Boser, I. Guyon, and V. Vapnik. A training algorithm for optimal margin classiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, pages 144152. ACM Press, 1992. C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2:27:127:27, 2011. Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm. C. Cortes and V. Vapnik. Support-vector network. Machine Learning, 20:273297, 1995. C. Drummond. Replicability is not reproducibility: Nor is it good science. In Proceedings of the Evaluation Methods for Machine Learning Workshop at the 26th ICML, 2009. R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin. LIBLINEAR: A library for large linear classication. Journal of Machine Learning Research, 9:18711874, 2008. URL http://www.csie.ntu.edu.tw/~cjlin/papers/liblinear.pdf. D. Goldberg. What every computer scientist should know about oating-point arithmetic. ACM Computing Surveys, 23(1):548, 1991. C.-J. Hsieh, K.-W. Chang, C.-J. Lin, S. S. Keerthi, and S. Sundararajan. A dual coordinate descent method for large-scale linear SVM. In Proceedings of the Twenty Fifth International Conference on Machine Learning (ICML), 2008. URL http://www.csie.ntu.edu.tw/~cjlin/papers/cddual.pdf.
Chih-Jen Lin (National Taiwan Univ.) 100 / 102
102

Discussion and conclusions
References II
C.-W. Hsu and C.-J. Lin. A comparison of methods for multi-class support vector machines. IEEE Transactions on Neural Networks, 13(2):415425, 2002. C.-W. Hsu, C.-C. Chang, and C.-J. Lin. A practical guide to support vector classication. Technical report, Department of Computer Science, National Taiwan University, 2003. URL http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf. T. Joachims. Making large-scale SVM learning practical. In B. Schlkopf, C. J. C. Burges, and o A. J. Smola, editors, Advances in Kernel Methods Support Vector Learning, pages 169184, Cambridge, MA, 1998. MIT Press. T. Joachims. Training linear SVMs in linear time. In Proceedings of the Twelfth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2006. S. S. Keerthi and C.-J. Lin. Asymptotic behaviors of support vector machines with Gaussian kernel. Neural Computation, 15(7):16671689, 2003. E. Osuna, R. Freund, and F. Girosi. Training support vector machines: An application to face detection. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pages 130136, 1997. J. C. Platt. Fast training of support vector machines using sequential minimal optimization. In B. Schlkopf, C. J. C. Burges, and A. J. Smola, editors, Advances in Kernel Methods o Support Vector Learning, Cambridge, MA, 1998. MIT Press.
Chih-Jen Lin (National Taiwan Univ.)
101 / 102
103

Discussion and conclusions
References III
S. Shalev-Shwartz, Y. Singer, and N. Srebro. Pegasos: primal estimated sub-gradient solver for SVM. In Proceedings of the Twenty Fourth International Conference on Machine Learning (ICML), 2007. S. Sonnenburg, M. Braun, C. Ong, S. Bengio, L. Bottou, G. Holmes, Y. LeCun, K. Mller, u F. Pereira, C. Rasmussen, et al. The need for open source software in machine learning. Journal of Machine Learning Research, 8:24432466, 2007. G.-X. Yuan, C.-H. Ho, and C.-J. Lin. Recent advances of large-scale linear classication. Proceedings of IEEE, 2012. URL http://www.csie.ntu.edu.tw/~cjlin/papers/survey-linear.pdf. To appear.
Chih-Jen Lin (National Taiwan Univ.)
102 / 102
104