Convergent Learning: Do different neural networks learn the same representations?
Quick links: ICLR 2016 arXiv (pdf) | code | Talk at NIPS 2015 FE Workshop | Talk at ICLR 2016
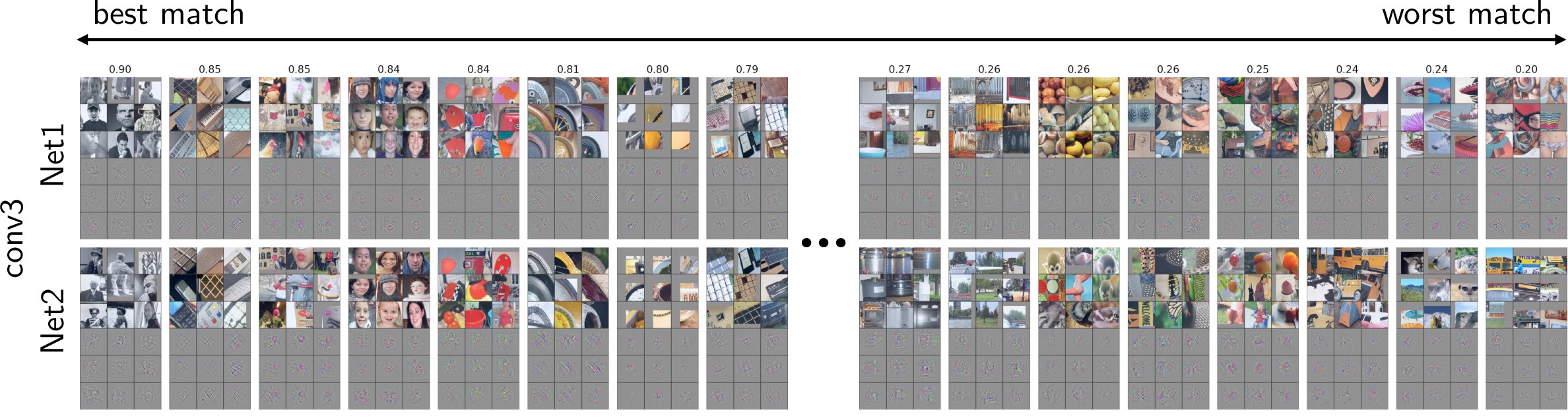
With assignments chosen by semi-matching (see paper), the eight best (highest correlation, left) and eight worst (lowest correlation, right) matched features between Net1 and Net2 for the conv3 layer. To visualize the functionality each unit, we plot the nine image patches (in a three by three block) from the validation set that causes the highest activation for that unit and directly beneath that block show the “deconv” visualization of each of the nine images. On the far left we can see that a single unit in each network was learned a local code (like a “Grandmother neuron”) for a concept that possibly be described as “black and white objects.” See all conv layers below.
Casual Abstract
Deep neural networks have recently been working really well, which has prompted active investigation into the features learned in the middle of the network. The investigation is hard because it requires making sense of millions of learned parameters. But it’s also valuable, because any understanding we acquire promises to help us build and train better models. In this paper we investigate the extent to which neural networks exhibit what we call convergent learning, which is when the representations learned by multiple nets converge to a set of features which are either individually similar between networks or where subsets of features span similar low-dimensional spaces. We probe representations by training multiple networks and then comparing and contrasting their individual, learned features at the level of neurons or groups of neurons. This initial investigation has led to several insights which you will find out if you read the paper.
Yixuan's Talk at the NIPS 2015 Feature Extraction Workshop
Yixuan presented the paper at the Feature Extraction workshop.
Slides from the talk: pdf.
Jason's talk at ICLR 2016
Jason presented the paper at ICLR 2016. Here is a video of the talk posted by the ICLR organizers:

There's also a rough Periscope video (originally posted here) that is unfortunately missing the first 30 seconds or so of the talk but that shows the slides and animations more clearly than the above. Thanks to those who posted the recording!
Slides from the talk: keynote, pdf.
Matches on all five conv layers

Posted May 3, 2016. Updated May 31, 2016.