Hi there!
I'm a scientist, hacker, engineer, founder, and occasional investor and adviser.
I'm currently working on building networks of little sensors that use machine learning to help wind farms produce more energy over at Windscape AI. If working on such things excites you, drop me a line!
My scientific work focuses on training, understanding, and improving neural networks.
I serve as president of the ML Collective research group, where we work on fun problems and try to make ML research more accessible to all by collaborating across traditional industrial and academic lab boundaries. If you're interested in learning more, stop by our open reading group on Friday!
I'm also a scientific advisor to Recursion Pharmaceuticals, and I invest in and advise a few other companies bringing ML to bear on real world problems.
Previously I helped start Uber AI Labs after Uber acquired our startup, Geometric Intelligence.
I completed my Ph.D. at Cornell, where at various times I worked with
Hod Lipson
(at the Creative Machines Lab),
Yoshua Bengio
(at U. Montreal's MILA), Thomas Fuchs (at Caltech JPL), and
Google DeepMind. I was fortunate to be supported
by a NASA Space Technology Research Fellowship, which gave me the opportunity to trek around and work with all these great folks.
Find me on Bluesky, Twitter, or Github if you'd like.
Research
👇 Below are some older projects. 👉 More recent ones are over at ML Collective.

Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
Anh Nguyen, Jeff Clune, Yoshua Bengio, Alexey Dosovitskiy, and Jason Yosinski
Methods that generate images by iteratively following class gradients in image space
in some cases have been used to produce unrealistic adversarial or fooling images (Szegedy et al, 2013, Nguyen et al, 2014) and in other cases have been used as pseudo-generative models to produce somewhat realistic images that show good global structure but still don't look fully natural (Yosinski et al, 2015) or do look natural but lack diversity (Nguyen et al. 2016). Deficiencies in previous approaches result in part from training and sampling methods that have just been hacked together to produce pretty pictures rather than designed from the ground up as a trainable, generative model.
In this paper, we formalize consistent training and sampling procedures for such models and as a result obtain much more diverse and visually compelling samples.
Read more »
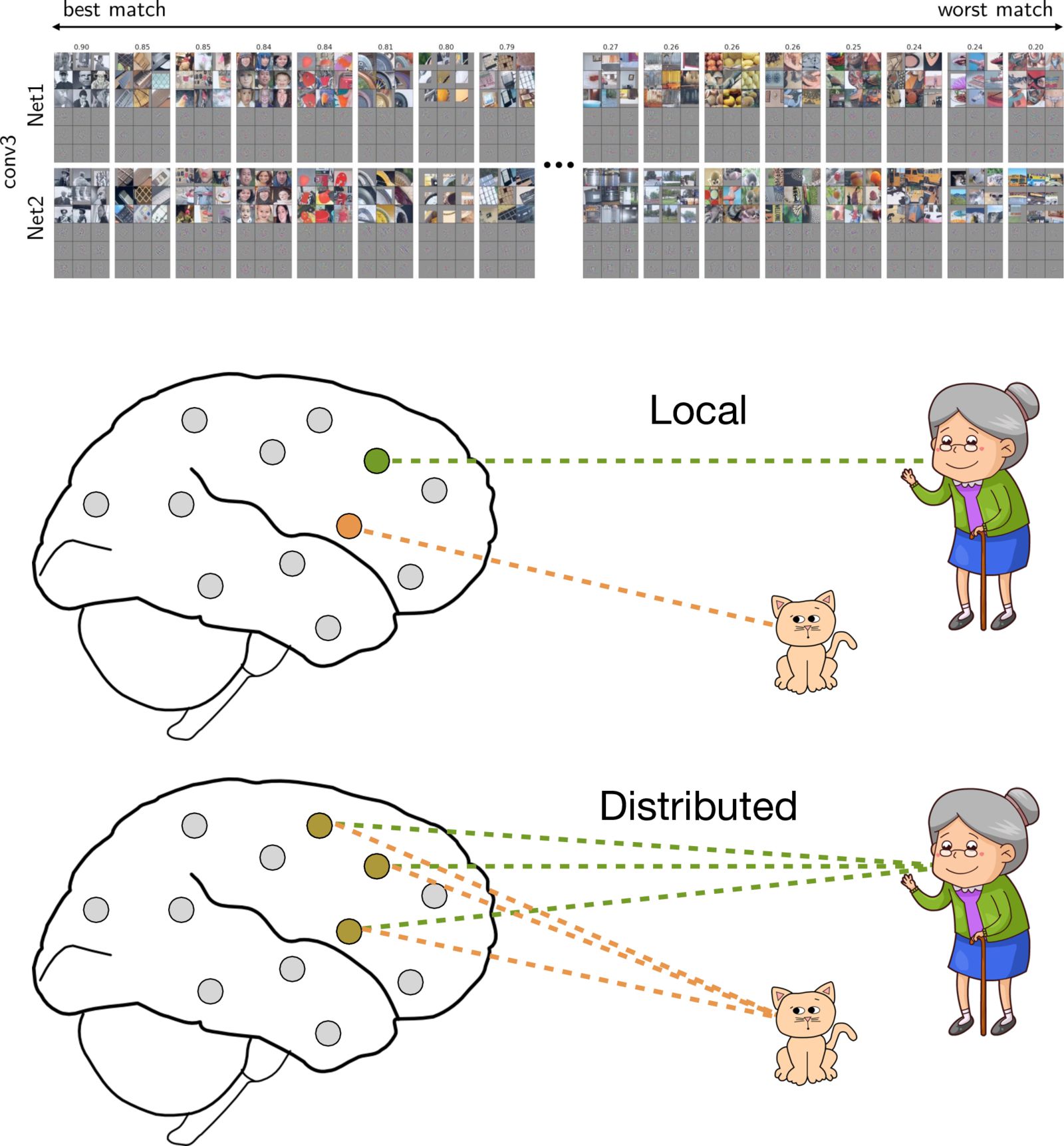
Convergent Learning: Do different neural networks learn the same representations?
Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John Hopcroft
Deep neural networks have recently been working really well, which has prompted active investigation into the features learned in the middle of the network. The investigation is hard because it requires making sense of millions of learned parameters. But it’s also valuable, because any understanding we acquire promises to help us build and train better models. In this paper we investigate the extent to which neural networks exhibit what we call convergent learning, which is when the representations learned by multiple nets converge to a set of features which are either individually similar between networks or where subsets of features span similar low-dimensional spaces. We probe representations by training multiple networks and then comparing and contrasting their individual, learned features at the level of neurons or groups of neurons. This initial investigation has led to several insights which you will find out if you read the paper.
Read more »
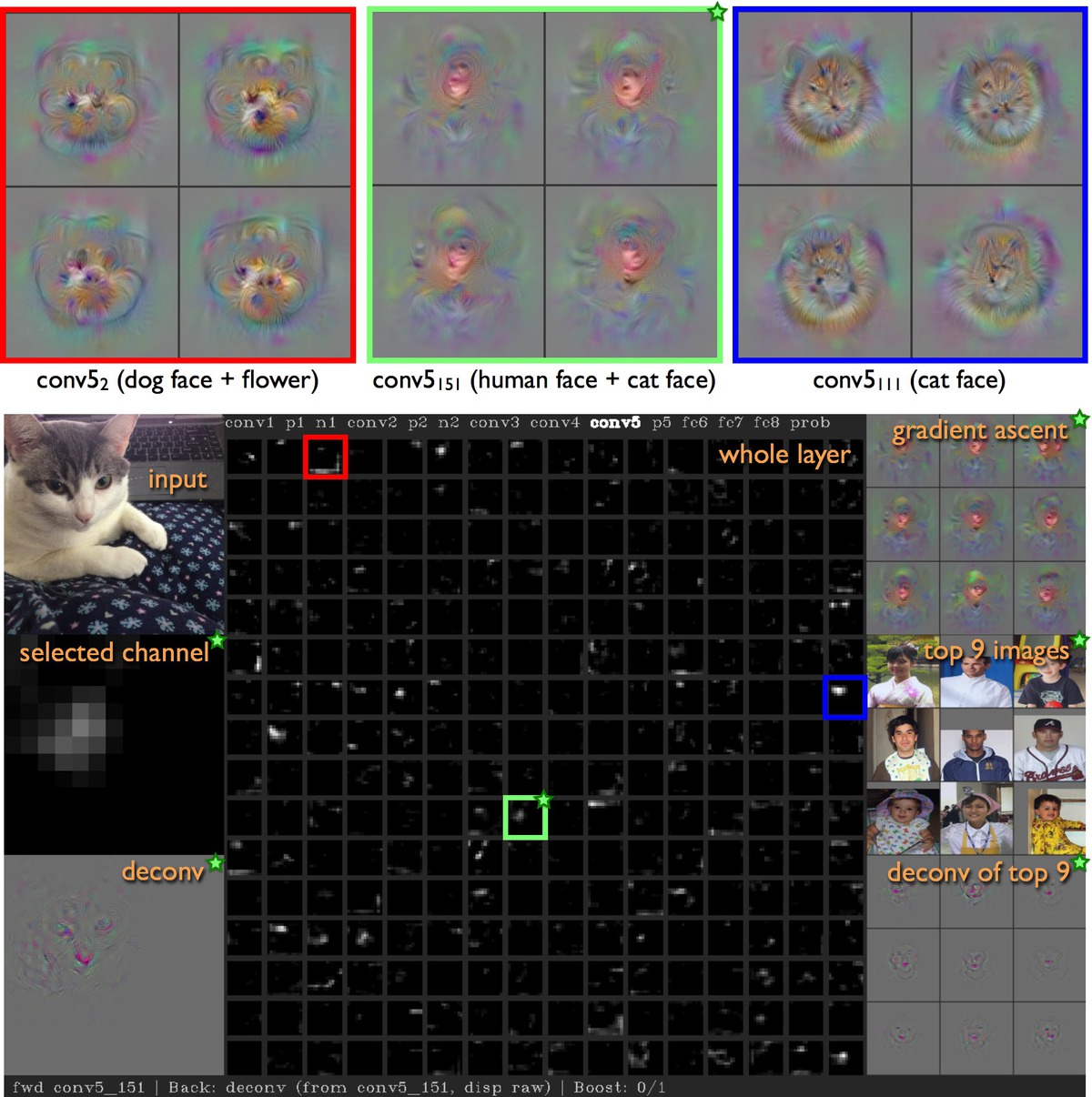
Understanding Neural Networks Through Deep Visualization
Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson
Recent years have produced great advances in training large, deep neural networks (DNNs), including notable successes in training convolutional neural networks (convnets) to recognize natural images. However, our understanding of how these models work, especially what computations they perform at intermediate layers, has lagged behind. Here we introduce two tools for better visualizing and interpreting neural nets. The first is a set of new regularization methods for finding preferred activations using optimization, which leads to clearer and more interpretable images than had been found before. The second tool is
an interactive toolbox that visualizes the activations produced on each layer of a trained convnet. You can input image files or read video from your webcam, which we've found fun and informative. Both tools are open source.
Read more »
Deep Neural Networks are Easily Fooled
Anh Nguyen, Jason Yosinski, and Jeff Clune
Deep neural networks (DNNs) have recently been doing very well at visual classification problems (e.g. recognizing that one image is of a lion and another image is of a school bus). A recent study by Szegedy et al. showed that changing an image (e.g. of a lion) in a way imperceptible to humans can cause a network to label the image as something else entirely (e.g. mislabeling a lion a library). Here we show a related result: it is easy to produce images that are completely unrecognizable to humans, but that state-of-the-art DNNs believe to be recognizable objects with 99.99% confidence (e.g. labeling with certainty that white noise static is a lion). We show methods of producing fooling images both with and without the class gradient in pixel space. The results shed light on interesting differences between human vision and state-of-the-art DNNs.
Read more »
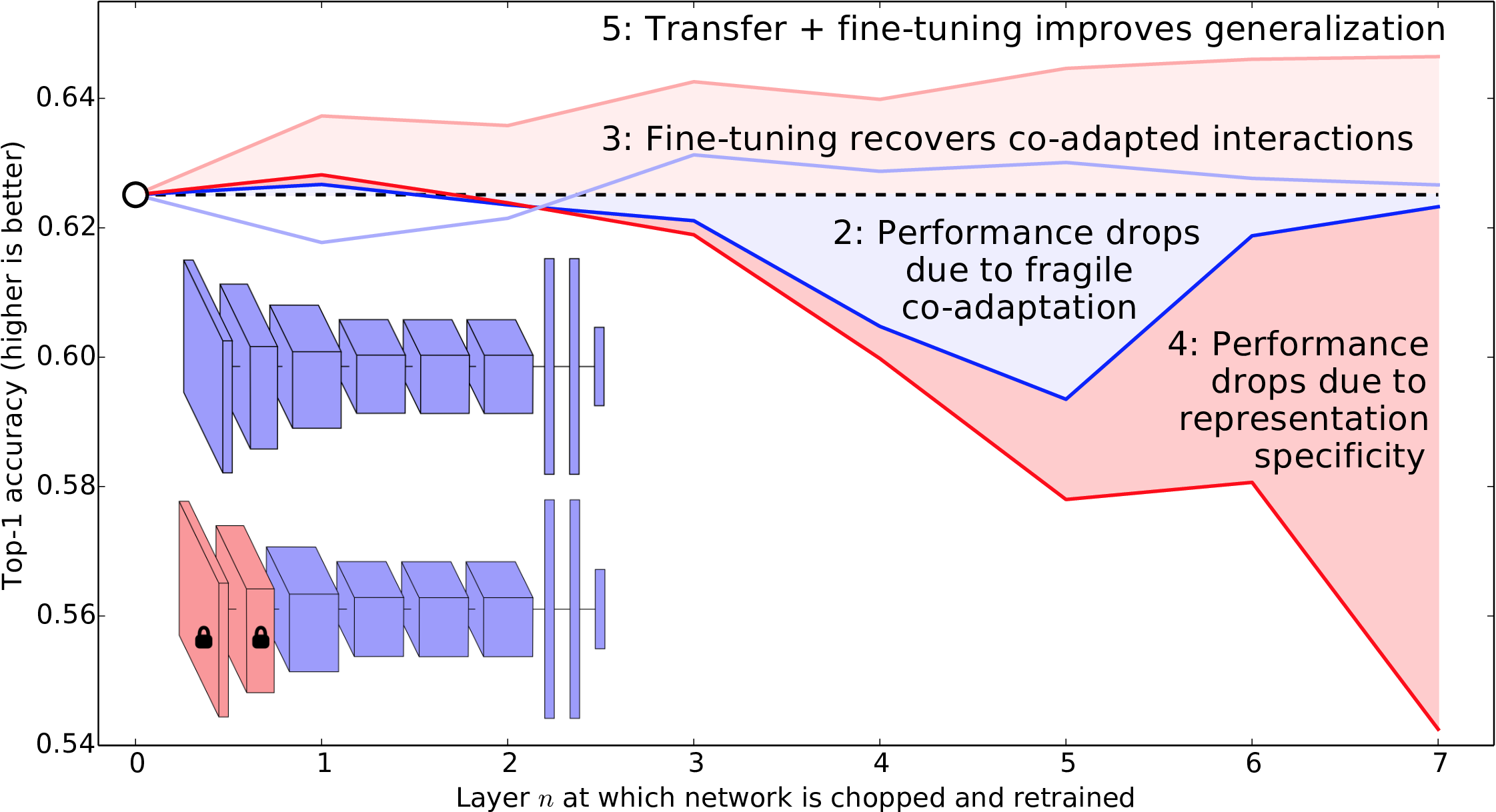
How Transferable are Features in Deep Neural Networks?
Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson
Many deep neural networks trained on natural
images exhibit a curious phenomenon: they all learn roughly the same Gabor filters
and color blobs on the first layer. These features seem to
be generic — useful for many datasets and tasks
— as opposed to specific — useful for only one
dataset and task. By the last layer features must be task specific,
which prompts the question: how do features transition from general
to specific throughout the network? In this paper, presented at NIPS
2014, we show the manner in which features transition from general
to specific, and also uncover a few other interesting results along
the way.
Read more »
Generative Stochastic Networks
Yoshua Bengio, Éric Thibodeau-Laufer, Guillaume Alain, and Jason Yosinski
Unsupervised learning of models for probability distributions
can be difficult due to intractable partition
functions. We introduce a general family of models called
Generative Stochastic
Networks (GSNs) as an
alternative to maximum likelihood. Briefly, we show how to learn the
transition operator of a Markov chain whose stationary distribution
estimates the data distribution. Because this transition distribution
is a conditional distribution, it's often much easier to learn than
the data distribution itself. Intuitively, this works by pushing
the complexity that normally lives in the partition function into the
“function approximation” part of the transition operator,
which can be learned via simple backprop. We validate the theory by
showing several successful experiments on two image datasets and with
a particular architecture that mimics the Deep Boltzmann Machine but
without the need for layerwise pretraining.
Aracna
Sara Lohmann*, Jason Yosinski*, Eric Gold, Jeff Clune, Jeremy Blum and Hod Lipson
(read the
paper) Many labs work on gait learning research, but since they each use different robotic
platforms to test out their ideas, it is hard to compare results
between these teams. To encourage greater collaboration between
scientists, we have developed
Aracna, an open-source, 3D printed platform that anyone can use for robotic
experiments.
AI vs. AI
Igor Labutov*, Jason Yosinski*, and Hod Lipson
As part of a class
project, Igor
Labutov and I cobbled together a speech-to-text + chatbot + text-to-speech system that could converse with a user. We
then hooked up two such systems, gave them names (Alan and Sruthi), and
let them talk together,
producing endless
robotic comedy. Somehow
the video became popular. There
was an XKCD about it, and Sruthi
even told Robert Siegel to “be afraid”
on NPR. Dress appropriately for the
coming robot uprising with one of our
fashionable t-shirts.
Gait Learning on QuadraTot
Jason Yosinski, Jeff Clune, Diana Hidalgo, Sarah Nguyen, Juan Zagal, and Hod Lipson
(read
the paper) Getting robots to walk is tricky. We compared many
algorithms for automating the creation of quadruped gaits, with all
the learning done in hardware (read: very time consuming). The best
gaits we found were nearly 9 times faster than a hand-designed gait
and exhibited complex motion patterns that contained multiple
frequencies, yet showed coordinated leg movement. More
recent work blends learning in simulation and reality to create
even faster gaits.
Nevermind all this, just show me the videos!
Or, if you prefer, here's a slightly outdated CV.
Selected Papersmore »
-

(pdf)
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, Rosanne Liu.
Plug and Play Language Models: a Simple Approach to Controlled Text Generation.
International Conference on Learning Representations (ICLR) 2020. 26 April 2020.
abstract▾ |
bib▾
Large transformer-based language models (LMs) trained on huge text corpora have shown unparalleled generation capabilities. However, controlling attributes of the generated language (e.g. switching topic or sentiment) is difficult without modifying the model architecture or fine-tuning on attribute-specific data and entailing the significant cost of retraining. We propose a simple alternative: the Plug and Play Language Model (PPLM) for controllable language generation, which combines a pretrained LM with one or more simple attribute classifiers that guide text generation without any further training of the LM. In the canonical scenario we present, the attribute models are simple classifiers consisting of a user-specified bag of words or a single learned layer with 100,000 times fewer parameters than the LM. Sampling entails a forward and backward pass in which gradients from the attribute model push the LM's hidden activations and thus guide the generation. Model samples demonstrate control over a range of topics and sentiment styles, and extensive automated and human annotated evaluations show attribute alignment and fluency. PPLMs are flexible in that any combination of differentiable attribute models may be used to steer text generation, which will allow for diverse and creative applications beyond the examples given in this paper.
@article{dathathri-2020-ICLR-plug-play-language-models,
Author = {Sumanth Dathathri and Andrea Madotto and Janice Lan and Jane Hung and Eric Frank and Piero Molino and Jason Yosinski and Rosanne Liu},
Journal = {International Conference on Learning Representations (ICLR)},
Month = {April},
Title = {{Plug and Play Language Models: a Simple Approach to Controlled Text Generation}},
Year = {2020}}
-

(pdf)
Sam Greydanus, Misko Dzamba, and Jason Yosinski.
Hamiltonian Neural Networks.
Advances in Neural Information Processing Systems (NeurIPS), 2019. 4 June 2019.
arXiv page.
abstract▾ |
bib▾
Even though neural networks enjoy widespread use, they still struggle to learn the basic laws of physics. How might we endow them with better inductive biases? In this paper, we draw inspiration from Hamiltonian mechanics to train models that learn and respect exact conservation laws in an unsupervised manner. We evaluate our models on problems where conservation of energy is important, including the two-body problem and pixel observations of a pendulum. Our model trains faster and generalizes better than a regular neural network. An interesting side effect is that our model is perfectly reversible in time.
@article{greydanus-2019-arXiv-hamiltonian-neural-networks,
Author = {{Greydanus}, Sam and {Dzamba}, Misko and {Yosinski}, Jason},
Journal = {arXiv e-prints},
Month = {Jun},
Pages = {arXiv:1906.01563},
Title = {{Hamiltonian Neural Networks}},
Year = {2019}}
-

(pdf)
Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson.
How transferable are features in deep neural networks?.
Advances in Neural Information Processing Systems 27 (NIPS '14), pages 3320 - 3328. 8 December 2014.
See also:
earlier arXiv version.
Oral presentation (1.2%).
abstract▾ |
bib▾
Many deep neural networks trained on natural images exhibit a curious phenomenon in common: on the first layer they learn features similar to Gabor filters and color blobs. Such first-layer features appear not to be specific to a particular dataset or task, but general in that they are applicable to many datasets and tasks. Features must eventually transition from general to specific by the last layer of the network, but this transition has not been studied extensively. In this paper we experimentally quantify the generality versus specificity of neurons in each layer of a deep convolutional neural network and report a few surprising results. Transferability is negatively affected by two distinct issues: (1) the specialization of higher layer neurons to their original task at the expense of performance on the target task, which was expected, and (2) optimization difficulties related to split- ting networks between co-adapted neurons, which was not expected. In an example network trained on ImageNet, we demonstrate that either of these two issues may dominate, depending on whether features are transferred from the bottom, middle, or top of the network. We also document that the transferability of features decreases as the distance between the base task and target task increases, but that transferring features even from distant tasks can be better than using random features. A final surprising result is that initializing a network with transferred features from almost any number of layers can produce a boost to generalization that lingers even after fine-tuning to the target dataset.
@inproceedings{yosinski_2014_NIPS
title={How transferable are features in deep neural networks?},
author={Yosinski, Jason and Clune, Jeff and Bengio, Yoshua and Lipson, Hod},
booktitle={Advances in Neural Information Processing Systems 27 (NIPS '14)},
editor = {Z. Ghahramani and M. Welling and C. Cortes and N.D. Lawrence and K.Q. Weinberger},
publisher = {Curran Associates, Inc.},
pages = {3320--3328},
year={2014}
}
-

(pdf)
Anh Nguyen, Jason Yosinski, and Jeff Clune.
Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images.
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 8 June 2015.
Oral presentation (3.3%), CVPR 2015 Community Top Paper Award.
See also:
arXiv page.
abstract▾ |
bib▾
Deep neural networks (DNNs) have recently been achieving state-of-the-art performance on a variety of pattern-recognition tasks, most notably visual classification problems. Given that DNNs are now able to classify objects in images with near-human-level performance, questions naturally arise as to what differences remain between computer and human vision. A recent study [30] revealed that changing an image (e.g. of a lion) in a way imperceptible to humans can cause a DNN to label the image as something else entirely (e.g. mislabeling a lion a library). Here we show a related result: it is easy to produce images that are completely unrecognizable to humans, but that state-of-the-art DNNs believe to be recognizable objects with 99.99% confidence (e.g. labeling with certainty that white noise static is a lion). Specifically, we take convolutional neural networks trained to perform well on either the ImageNet or MNIST datasets and then find images with evolutionary algorithms or gradient ascent that DNNs label with high confidence as belonging to each dataset class. It is possible to produce images totally unrecognizable to human eyes that DNNs believe with near certainty are familiar objects, which we call "fooling images" (more generally, fooling examples). Our results shed light on interesting differences between human vision and current DNNs, and raise questions about the generality of DNN computer vision.
@article{nguyen-2015-CVPR-deep-neural-networks,
Author = {Nguyen, Anh and Yosinski, Jason and Clune, Jeff},
Journal = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
Month = {June},
Title = {Deep Neural Networks Are Easily Fooled: High Confidence Predictions for Unrecognizable Images},
Year = {2015}}
-

(pdf)
Yoshua Bengio, Éric Thibodeau-Laufer, Guillaume Alain, Jason Yosinski.
Deep Generative Stochastic Networks Trainable by Backprop.
Proceedings of the International Conference on Machine Learning. 21 June 2014.
See also:
supplemental section,
earlier and later arXiv versions.
abstract▾ |
bib▾
We introduce a novel training principle for probabilistic models that is an alternative to maximum likelihood. The proposed Generative Stochastic Networks (GSN) framework is based on learning the transition operator of a Markov chain whose stationary distribution estimates the data distribution. The transition distribution of the Markov chain is conditional on the previous state, generally involving a small move, so this conditional distribution has fewer dominant modes, being unimodal in the limit of small moves. Thus, it is easier to learn because it is easier to approximate its partition function, more like learning to perform supervised function approximation, with gradients that can be obtained by backprop. We provide theorems that generalize recent work on the probabilistic interpretation of denoising autoencoders and obtain along the way an interesting justification for dependency networks and generalized pseudolikelihood, along with a definition of an appropriate joint distribution and sampling mechanism even when the conditionals are not consistent. GSNs can be used with missing inputs and can be used to sample subsets of variables given the rest. We validate these theoretical results with experiments on two image datasets using an architecture that mimics the Deep Boltzmann Machine Gibbs sampler but allows training to proceed with simple backprop, without the need for layerwise pretraining.
@inproceedings{bengio_icml_2014_deep-generative-stochastic-networks,
title={Deep Generative Stochastic Networks Trainable by Backprop},
author={Bengio, Yoshua and Thibodeau-Laufer, Eric and Alain, Guillaume and Yosinski, Jason},
booktitle={Proceedings of the International Conference on Machine Learning},
year={2014}
}
-

(pdf)
Jeff Clune, Jason Yosinski, Eugene Doan, and Hod Lipson.
EndlessForms.com: Collaboratively Evolving Objects and 3D Printing Them.
Proceedings of the 13th International Conference on the Synthesis and Simulation of Living Systems. 21 July 2012.
Winner of Best Poster award.
abstract▾ |
bib▾
This abstract introduces EndlessForms.com, the first website to allow users to interactively evolve three-dimensional (3D) shapes online. Visitors are able to evolve objects that resemble natural organisms and engineered designs because the site utilizes a relatively new generative encoding inspired by concepts from developmental biology (Figure 1). This Compositional Pattern Producing Network (CPPN) encoding abstracts how natural organisms grow from a single cell to complex morphologies. Once evolved, visitors can click a button and have their evolved design 3D printed in materials ranging from plastic to silver. The site takes advantage of a recently released Web technology technology called WebGL that enables the visualization of 3D objects in Internet browsers. EndlessForms.com thus brings together recent innovations in evolutionary computation, Web technologies, and 3D printing to create a powerful collaborative interactive evolution experience that was not possible as recently as a year ago. In the first year of its release, nearly 3 million objects have been evaluated on the site during 190,000 generations of interactive evolution. A sizable community of citizen scientist participated: there were over 40,000 unique visitors from 150 countries and all 50 US states. In addition to its scientific mission of fueling intuitions regarding generative encodings for evolutionary algorithms, EndlessForms serves an educational outreach goal: visitors learn about evolution and developmental biology in a fun virtual setting and can transfer the 3D objects they create to the physical world (Figure 2).
View a video tour of EndlessForms at http://goo.gl/YvoBw
@inproceedings{clune2012endlessforms.com:-collaboratively-evolving-objects,
Author = {Jeff Clune and Jason Yosinski and Eugene Doan and Hod Lipson},
Booktitle = {Proceedings of the 13th International Conference on the Synthesis and Simulation of Living Systems},
Title = {EndlessForms.com: Collaboratively Evolving Objects and 3D Printing Them},
Year = {2012}
}
-

(pdf)
Jason Yosinski, Jeff Clune, Diana Hidalgo, Sarah Nguyen, Juan Cristobal Zagal, and Hod Lipson.
Evolving Robot Gaits in Hardware: the HyperNEAT Generative Encoding Vs. Parameter Optimization.
Proceedings of the 20th European Conference on Artificial Life, Paris, France. pp 890-897. 8 August 2011.
abstract▾ |
bib▾
Creating gaits for legged robots is an important task to enable robots
to access rugged terrain, yet designing such gaits by hand is a
challenging and time-consuming process. In this paper we investigate
various algorithms for automating the creation of quadruped
gaits. Because many robots do not have accurate simulators, we test
gait-learning algorithms entirely on a physical robot. We compare the
performance of two classes of gait-learning algorithms: locally searching
parameterized motion models and evolving artificial neural networks
with the HyperNEAT generative encoding. Specifically, we test six
different parameterized learning strategies: uniform and Gaussian
random hill climbing, policy gradient reinforcement learning,
Nelder-Mead simplex, a random baseline, and a new method that builds a
model of the fitness landscape with linear regression to guide further
exploration. While all parameter search methods outperform a
manually-designed gait, only the linear regression and Nelder-Mead
simplex strategies outperform a random baseline strategy. Gaits
evolved with HyperNEAT perform considerably better than all
parameterized local search methods and produce gaits nearly 9 times
faster than a hand-designed gait. The best HyperNEAT gaits exhibit
complex motion patterns that contain multiple frequencies, yet are
regular in that the leg movements are coordinated.
@InProceedings{Yosinski2011EvolvedGaits,
author = {Jason Yosinski and Jeff Clune and Diana Hidalgo and Sarah Nguyen and Juan Cristobal Zagal and Hod Lipson},
title = {Evolving Robot Gaits in Hardware: the HyperNEAT Generative Encoding Vs. Parameter Optimization},
booktitle = {Proceedings of the 20th European Conference on Artificial Life},
year = {2011},
month = {August},
numpages = {8},
location = {Paris, France},
}
Google scholar |
see all 41 papers and posters »
Selected Pressmore »
Through the Wormhole with Morgan Freeman: Through the Wormhole with Morgan Freeman: Are Robots the Future of Human Evolution? See our walking robots from 7:00 - 7:45 and 9:40 - 11:10. (Season 4, episode 7. unreliable video link) July 10, 2013
see more press »
Miscellaneous
Before grad school, I did my undergrad
at Caltech and then worked on
estimation at a research-oriented applied math
startup for a couple years.