References
Fukumizu, K., Bach, F.R., and Jordan, M.I. (2004) Dimensionality reduction for supervised learning with reproducing kernel Hilbert spaces. Journal of Machine Learning Research. 5:73-99, Fukumizu, K., F.R. Bach and M. Jordan. (2009) Kernel dimension reduction in regression. Annals of Statistics. 37(4), pp.1871-1905 Fukumizu, K., L. Song, A. Gretton (2011) Kernel Bayes' Rule. Advances in Neural Information Processing Systems 24 (NIPS2011) 1737-1745. Gretton, A., K.M. Borgwardt, M.Rasch, B. Schlkopf, A.J. Smola (2007) A Kernel Method for the Two-Sample-Problem. Advances in Neural Information Processing Systems 19, 513-520. Gretton, A., Z. Harchaoui, K. Fukumizu, B. Sriperumbudur (2010) A Fast, Consistent Kernel Two-Sample Test. Advances in Neural Information Processing Systems 22, 673-681. Gretton, A., K. Fukumizu, C.-H. Teo, L. Song, B. Schlkopf, A. Smola. (2008) A Kernel Statistical Test of Independence. Advances in Neural Information Processing Systems 20, 585-592. Gretton, A., K. Fukumizu, C.-H. Teo, L. Song, B. Schlkopf, A. Smola. (2008) A Kernel Statistical Test of Independence. Advances in Neural Information Processing Systems 20, 585-592. V-53









![Slide: Example 1: Principal component analysis (PCA)
PCA: project data onto the subspace with largest variance. 1st direction =
argmax ||a||1Var[a T X ]
Var[a T X ] T (i ) 1 a X N i 1 a T VXX a. 1 N
N
X ( j ) j 1
N
2
where
1 VXX N (i ) 1 X N i 1
N
1 X ( j ) X ( i ) j 1 N
N
X ( j) j 1
N
T
(Empirical) covariance matrix of
I-6](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_009.png)


![Slide: Another example: correlation
XY
Cov[ X , Y ] E X E[ X ]Y E[Y ] 2 2 Var[ X ]Var[Y ] E X E[ X ] E Y E[Y ]
3
2
= 0.94
1
Y
0
-1
-2
-3 -3
-2
-1
0
1
2
3
X
I-10](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_013.png)













![Slide: Principal Component Analysis
PCA (review)
Linear method for dimension reduction of data Project the data in the directions of large variance. 1st principal axis = argmax||a|| =1Var[ a X ]
T
1 n T 1 n T Var[a X ] = a X i j =1 X j n i =1 n
= a T VXX a.
where
1 n 1 n 1 n = X i j =1 X j X i j =1 X j n i =1 n n
T
2
VXX
II-4](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_028.png)
![Slide: From PCA to Kernel PCA
Kernel PCA: nonlinear dimension reduction of data 1998). Do PCA in feature space
(Schlkopf et al.
max ||a||=1 :
Var[a T X ] =
1 T 1 n a X i s =1 X s n i =1 n
n
2
max || f ||H =1 : Var[ f , ( X ) ] =
1 1 n f , ( X i ) s =1 ( X s ) n i =1 n
n
2
II-5](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_029.png)
![Slide: It is sufficient to assume
Orthogonal directions to the data can be neglected, since for 1 = ( ) + , where is orthogonal to =1 =1 }=1, the objective function of kernel the span{ PCA does not depend on .
1 =1
=
=1
1
=1
Then,
~2 Var[ f , ( X ) ] = cT K X c 2 T ~ || f ||H = c K X c
[Exercise] (centered Gram matrix)
~ ~ ~ where K X , ij := ( X i ), ( X j )
with
n ~ 1 ( X i ) := ( X i ) n s =1 ( X s )
(centered feature vector)
II-6](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_030.png)
![Slide: Objective function of kernel PCA
~2 max c K X c
T
subject to
~ c KX c = 1
T
The centered Gram matrix is expressed with Gram matrix = , as 1 =
1 n = k ( X i , X j ) s =1 k ( X i , X s ) ij n 1 n 1 t =1 k ( X t , X j ) + 2 n n [Exercise] ~ KX
( )
1
1 = 1
N
= Unit matrix
t , s =1
k( Xt , X s )
II-7](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_031.png)


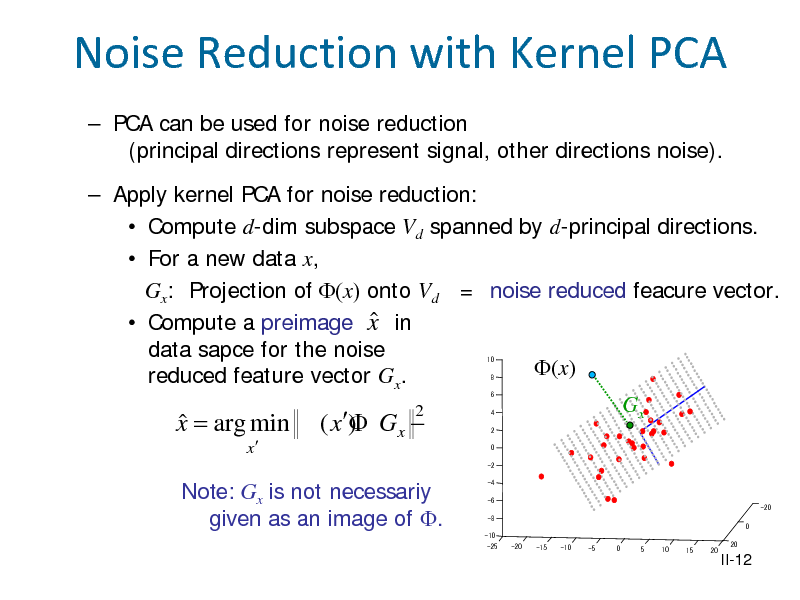



![Slide: Canonical Correlation Analysis
Canonical correlation analysis (CCA, Hotelling 1936) Linear dependence of two multivariate random vectors. Data 1 , 1 , , ( , ) : m-dimensional, : -dimensional
Find the directions and so that the correlation of and is maximized.
= max Corr[a X , b Y ] = max
T T a ,b a ,b
Cov[a T X , bT Y ]
T
Var[a X ]Var[b Y ]
T
,
a X
a TX
b TY
b Y
II-16](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_040.png)
![Slide: Solution of CCA
,
Rewritten as a generalized eigenproblem:
max
subject to
[Exercise: derive this. (Hint. Use Lagrange multiplier method.)] Solution: = 1 , = 1
1/2 1/2
=
= = 1.
where 1 (1 , resp.) is the left (right, resp.) first eigenvector 1/2 1/2 . for the SVD of
II-17](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_041.png)
![Slide: Kernel CCA
Kernel CCA (Akaho 2000, Melzer et al. 2002, Bach et al 2002) Dependence (not only correlation) of two random variables. Data: 1 , 1 , , ( , ) arbitrary variables Consider CCA for the feature vectors with and : 1 , , 1 , , , , 1 , , 1 , , .
max Var Var[ ] Cov[ , ] =
,
,
max
,
, ,
2
,
2
X
x
x(X)
f
f (X )
g (Y )
g
y(Y)
y
Y
II-18](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_042.png)









![Slide: 1 , 1 , , , : data : positive definite kernel for , : corresponding RKHS. : monotonically increasing function on + . Theorem 2.1 (representer theorem, Kimeldorf & Wahba 1970) The solution to the minimization problem: is attained by = =1
Representer theorem
min (1 , 1 , 1 , , ( , , )) + (| |)
The proof is essentially the same as the one for the kernel ridge regression. [Exercise: complete the proof]
II-30
with some 1 , , .](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_054.png)










![Slide: Exercise for kernel PCA
~ || f ||2 = cT K X c H
2
= ,
=1
2 Var f , ( X ) = cT K X c
[
Var ,
]
=1
= ,
2
= .
~
=
1 = , =
=1 =1 =1
1 ,
=1 =1
1 1 2 =
=1
,
II-43](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_067.png)


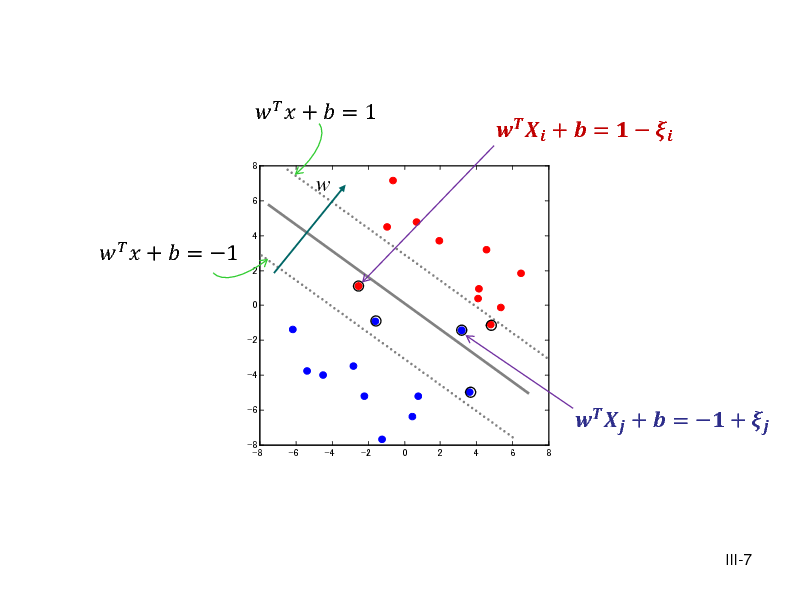
![Slide: Fix the scale (rescaling of (, ) does not change the plane) Then
min( wT X i + b) = 1 if Yi = 1, max( wT X i + b) = 1 if Yi = 1
2 Margin =
[Exercise] Prove this.
III-4](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_071.png)


![Slide: SVM and regularization
Soft-margin SVM is equivalent to the regularization problem: min 1 +
, =1 +
loss
+
regularization term
+
2
loss function: Hinge loss
c.f. Ridge regression (squared error)
, 2
, = 1
min + =1
+
= max{0, }
+
2
[Exercise] Confirm the above equivalence.
III-8](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_075.png)



![Slide: KKT condition
Theorem The solution of the primal and dual problem of SVM is given by the following equations: (1) (2) (3) (4) (6) (7) 1 + 0 ( ) 0 ( ) 0 , ( ) (1 ( + ) ) = 0 ( ) = 0 ( ), = 0, =1
[primal constraint] [primal constraint] [dual constraint] [complementary] [complementary]
(8) = 0, =1
III-12](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_079.png)





![Slide: -valued Positive definite kernel
Definition. : set. k : C is a positive definite kernel if for arbitrary 1, , and 1 , , ,
n
i , j =1 i
c c j k ( xi , x j ) 0.
Remark: From the above condition, the Gram matrix , necessarily Hermitian, i.e. , = (, ). [Exercise]
is
IV-2](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_086.png)


![Slide: Normalization
Proposition 4.3 Let be a positive definite kernel on , and : be an arbitrary function. Then, is positive definite. In particular, , : = , () ()
is a positive definite kernel. Proof [Exercise] Example. Normalization: , =
is positive definite, and () = 1 for any .
(, )(, )
,
IV-5](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_089.png)





![Slide: Polynomial kernel on : , = + ,
, 0 = 0 +
RKHS by polynomial kernel
2 2 1 1 + + . 0 1 + 0 1 2 0,
Span of these functions are polynomials of degree .
Proposition 4.5 If 0, the RKHS is the space of polynomials of degree at most . [Proof: exercise. Hint. Find to satisfy , = =0 =0 as a solution to a linear equation.]
IV-11](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_095.png)









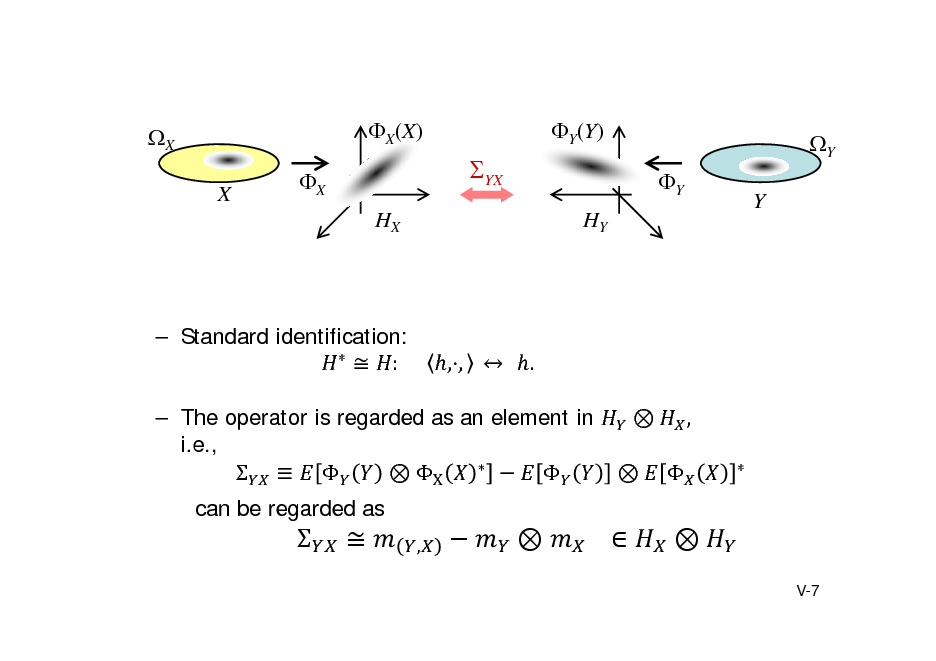
![Slide: Covarianceoperator
, : random variable taking values on , , resp. , , , : RKHS given by kernels on and , resp. Definition. Cross-covariance operator: YX : H X H Y
, :
,
denotes the linear functional
Simply, covariance of feature vectors. c.f. Euclidean case VYX = E[YXT] E[Y]E[X]T : covariance matrix Reproducing covariance:
g , YX f E[ g (Y ) f ( X )] E[ g (Y )]E[ f ( X )] ( Cov[ f ( X ), g (Y )])
for all , .
V-6](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_105.png)
![Slide: Characteristickernel
(Fukumizu,Bach,Jordan2004,2009;Sriperumbudur etal2010)
Kernel mean can capture higher-order moments of the variable. Example X: R-valued random variablek: pos.def. kernel on R. Suppose k admits a Taylor series expansion on R.
k (u , x) c0 c1 ( xu ) c2 ( xu ) 2
(ci > 0)
e.g.) k ( x, u ) exp( xu )
The kernel mean mX works as a moment generating function:
m X (u ) E[k (u , X )] c0 c1 E[ X ]u c2 E[ X 2 ]u 2
1 d m X (u ) E[ X ] c du u 0
V-8](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_107.png)

![Slide: Analogy to characteristic function With Fourier kernel F ( x, y ) exp 1 x T y
Ch.f. X (u) E[ F ( X , u)].
The characteristic function uniquely determines a Borel probability on Rm. The kernel mean m X (u ) E[ k (u , X )] with a characteristic kernel uniquely determines a probability on (, B). Note: may not be Euclidean.
The characteristic RKHS must be large enough! Examples for Rm (proved later): Gaussian, Laplacian kernel. Polynomial kernels are not characteristic.
V-10](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_109.png)

![Slide: EmpiricalEstimation
Empirical kernel mean
An advantage of RKHS approach is easy empirical estimation.
X 1 ,..., X n : i.i.d.
X 1 ,, X n
: sample on RKHS
Empirical mean:
m(Xn )
1 n 1 n ( X i ) k ( , X i ) n i 1 n i 1
-consistency) Theorem 5.1 (strong Assume E[ k ( X , X )] .
m (Xn ) m X O p 1
n
( n ).
V-12](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_111.png)



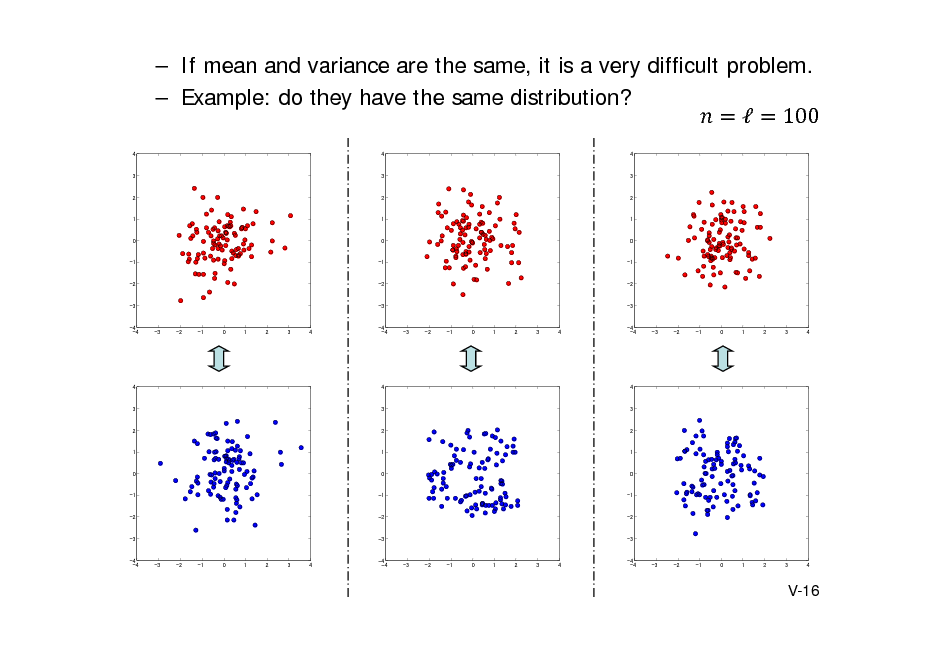
![Slide: Kernel method for two-sample problem
(Gretton et al. NIPS 2007, 2010, JMLR2012).
Kernel approach
Comparison of and comparison of and .
Maximum Mean Discrepancy
In population
MMD 2 m X mY
2 H
~ ~ E[k ( X , X )] E[k (Y , Y )] 2 E[k ( X , Y )].
( , : independent copy of , )
m X mY
H
sup
f :|| f ||H 1
f , m X mY sup
f :|| f ||H 1
f ( x )dP( x ) f ( x )dQ ( x )
hence, MMD.
With characteristic kernel, MMD = 0 if and only if
.
V-17](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_116.png)

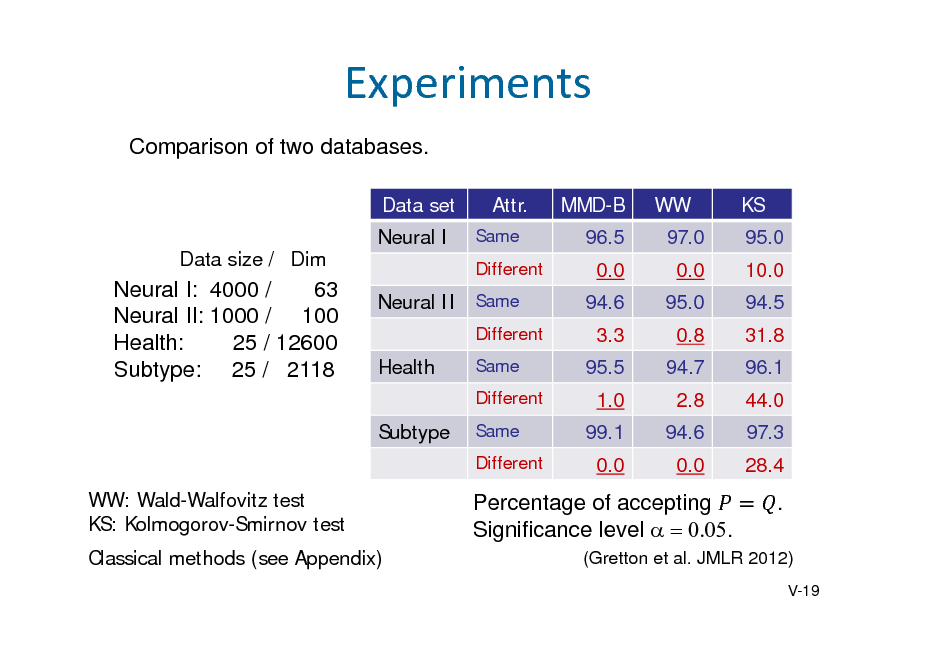
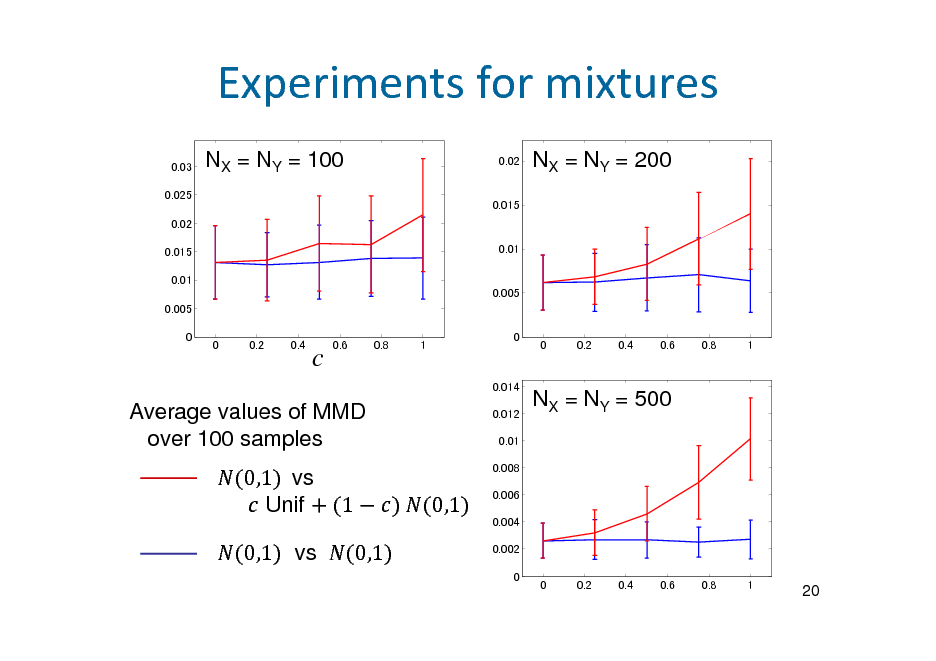

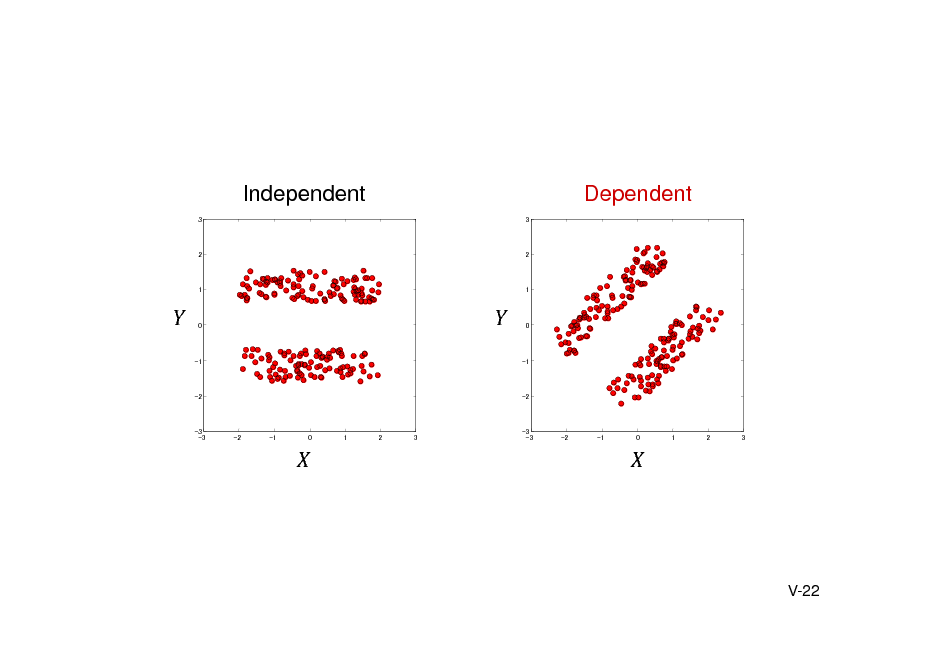
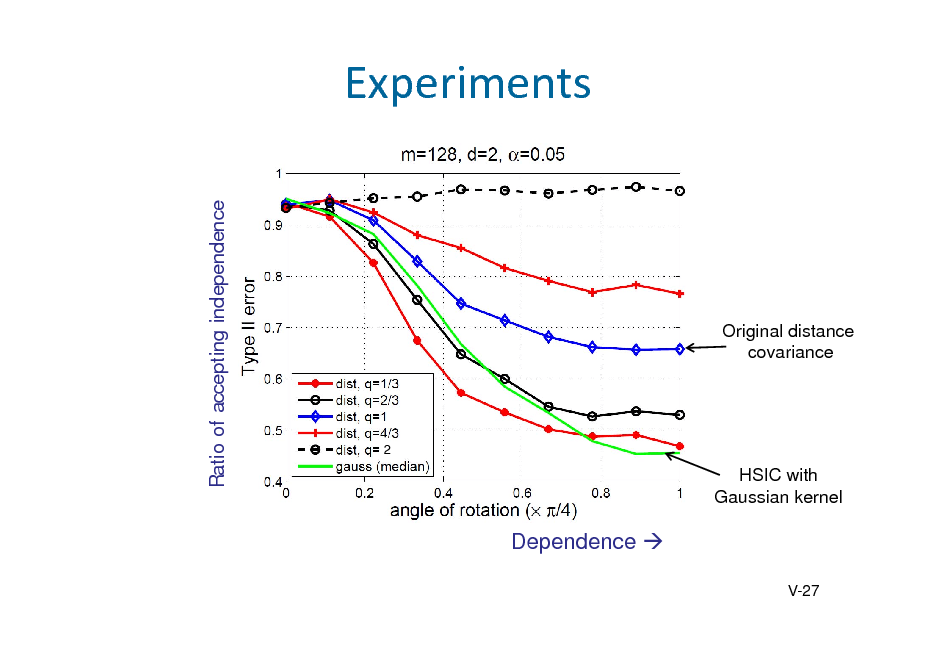
![Slide: Independencewithkernel
Theorem 5.3. (Fukumizu, Bach, Jordan, JMLR 2004) If the product kernel is characteristic, then
X Y YX O
Recall . Comparison between (kernel mean of (kernel mean of ). ) and
Dependence measure: Hilbert-Schmidt independence criterion , , 2
, : independent copy of ,
[Exercise]
, ,
.
, ,
,
V-23](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_122.png)











![Slide: An interpretation: Compare the conditional kernel means for , and | . |
Dependence on
is not easy to handle Average it out. | ]
Empirical estimator: |
V-36](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_135.png)



![Slide: Gradientbasedmethod
(Samarov 1993;Hristache etal2001)
Average Derivative Estimation (ADE)
Assumptions: Y is one dimensional EDR space p (Y | X ) ~ (Y | B T X ) p
~ ( y | B T x)dy B y ~ ( y | z ) T dy E[Y | X x] yp z p zB x x x
Gradient of the regression function lies in the EDR space at each x
B = average or PCA of the gradients at many x.
V-41](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_140.png)

![Slide: Derivativewithkernel
Reproducing the derivative (e.g. Steinwart & Christmann, Chap. 4):
k X ( , x ) k X ( x, ~ ) is differentiable and x Assume H X then x
k X ( , x ) f ( x ) f, x x
for any
Combining with the estimation of conditional kernel mean, ij ( x ) E [ Y (Y ) | X x ] , E [ Y (Y ) | X x ] M x i x j
k ( , x ) k ( , x ) CYX (C XX n I ) 1 X , CYX (C XX n I ) 1 X xi x j
The top eigenvectors of estimates the EDR space
V-43](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_142.png)

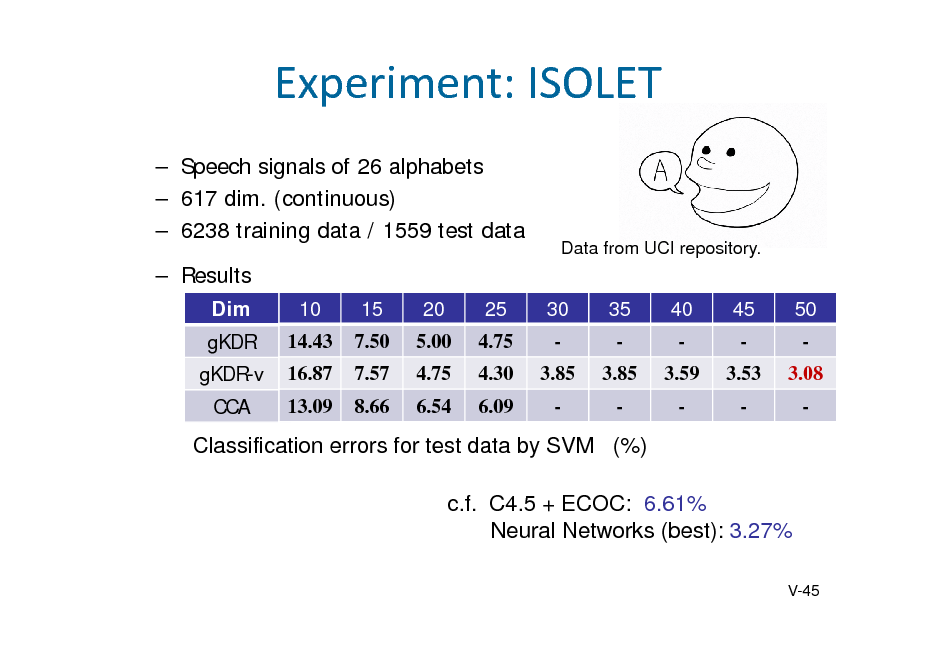

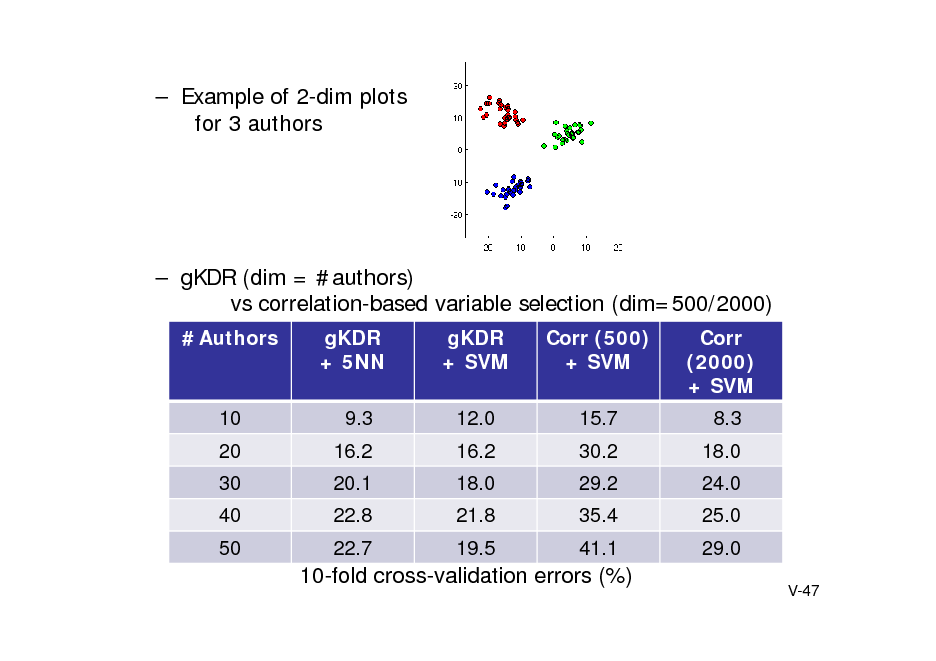



![Slide: Camera angles
Hidden : angles of a video camera located at a corner of a room. Observed : movie frame of a room + additive Gaussian noise. : 3600 downsampled frames of 20 x 20 RGB pixels (1200 dim. ). The first 1800 frames for training, and the second half for testing
noise
KBR (Trace) 0.15 0.01
Kalman filter(Q) 0.56 0.54 0.02 0.02
2 = 10-4 2 = 10-3
0.21 0.01
Average MSE for camera angles (10 runs) To represent SO(3) model, Tr[AB-1] for KBR, and quaternion expression for Kalman filter are used .
V-51](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_150.png)






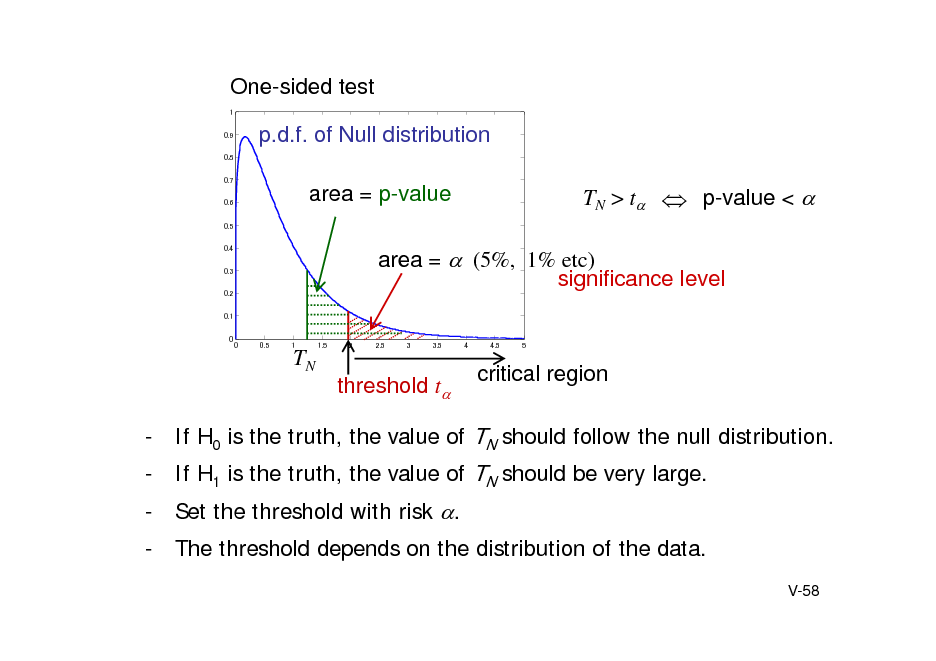




![Slide: Wald-Wolfowitz run test
One-dimensional samples Combine the samples and plot the points in ascending order. Label the points based on the original two groups. Count the number of runs, i.e. consecutive sequences of the same label. Test statistics R = Number of runs
TN
R E[ R ] Var[ R ]
N (0,1)
R = 10
In one-dimensional case, less powerful than KS test
Multidimensional extension of KS and WW test
Minimum spanning tree is used (Friedman Rafsky 1979)
V-63](https://yosinski.com/mlss12/media/slides/MLSS-2012-Fukumizu-Kernel-Methods-for-Statistical-Learning_162.png)